
🤖 [Transformer] Attention Is All You Need
![]() Updated:
Updated:
🔭 Overview
Transformer는 2017년 Google이 NIPS에서 발표한 자연어 처리용 신경망으로 기존 RNN 계열(LSTM, GRU) 신경망이 가진 문제를 해결하고 최대한 인간의 자연어 이해 방식을 수학적으로 모델링 하려는 의도로 설계 되었다. 이 모델은 초기 Encoder-Decoder 를 모두 갖춘 seq2seq 형태로 고안 되었으며, 다양한 번역 테스크에서 SOTA를 달성해 주목을 받았다. 이후에는 여러분도 잘 아시는 것처럼 BERT, GPT, ViT의 베이스 라인으로 채택 되며, 현대 딥러닝 역사에 한 획을 그은 모델로 평가 받고 있다.
현대 딥러닝의 전성기를 열어준 Transformer는 어떤 아이디어로 기존 Recurrent 계열이 가졌던 문제들을 해결했을까?? 이것을 제대로 이해하려면 먼저 기존 순환 신경망 모델들이 가졌던 문제부터 짚고 넘어갈 필요가 있다.
🤔 Limitation of Recurrent Structure
- 1) 인간과 다른 메커니즘의 Vanishing Gradient 발생 (Activation Function with Backward)
- 2) 점점 흐려지는 Inputs에 Attention (Activation Function with Forward)
- 3) 디코더가 가장 마지막 단어만 열심히 보고
denoising수행 (Seq2Seq with Bi-Directional RNN)
📈 1) 인간과 다른 메커니즘의 Vanishing Gradient 발생 (Activation Function with Backward)
RNN의 활성 함수인 Hyperbolic Tangent 는 $y$값이 [-1, 1] 사이에서 정의되며 기울기의 최대값은 1이다. 따라서 이전 시점 정보는 시점이 지나면 지날수록 (더 많은 셀을 통과할수록) 그라디언트 값이 작아져 미래 시점의 학습에 매우 작은 영향력을 갖게 된다. 이것이 바로 그 유명한 RNN의 Vanishing Gradient 현상이다. 사실 현상의 발생 자체는 그렇게 큰 문제가 되지 않는다. RNN에서 발생하는 Vanishing Gradient 가 문제가 되는 이유는 바로 인간이 자연어를 이해하는 메커니즘과 다른 방식으로 현상이 발생하기 때문이다. 우리가 글을 읽는 과정을 잘 떠올려 보자. 어떤 단어의 의미를 알기 위해 가까운 주변 단어의 문맥을 활용할 때도 있지만, 저 멀리 떨어진 문단의 문맥을 활용할 때도 있다. 이처럼 단어 혹은 시퀀스를 구성하는 원소 사이의 관계성이나 어떤 다른 의미론적인 이유로 불균형하게 현재 시점의 학습에 영향력을 갖게 되는게 아니라, 단순 입력 시점 때문에 불균형이 발생하기 때문에 RNN의 Vanishing Gradient가 낮은 성능의 원인으로 지목되는 것이다.
다시 말해, 실제 자연어의 문맥을 파악해 그라디언트에 반영하는게 아니라 단순히 시점에 따라서 그 영향력을 반영하게 된다는 것이다. 멀리 떨어진 시퀀스의 문맥이 필요한 경우를 Recurrent 구조는 정확히 학습할 수 없다.
그렇다면 활성 함수를 relu 혹은 gelu 를 사용하면 위 문제를 해결할 수 있을까? Vanishing Graident 문제는 해결할 수도 있으나 hidden_state 값이 발산할 것이다. 그 이유는 두 활성 함수 모두 양수 구간에서 선형인데, 이전 정보를 누적해서 가중치와 곱하고 현재 입력값에 더하는 RNN의 구조를 생각해보면 넘어오는 이전 정보는 누적되면서 점점 커질 것이고 그러다 결국 발산하게 된다.
결론적으로 Vanishing Gradient 현상 자체가 문제는 아니지만 모델이 자연어의 문맥을 파악해 그라디언트에 반영하는게 아니라 단순히 시점에 따라서 불균형하게 발생하기 때문에 낮은 성능의 원인으로 지목 받는 것이다. 이것을 long-term dependency라고 부르기도 한다.
✏️ 2) 점점 흐려지는 Inputs에 Attention (Activation Function with Forward)
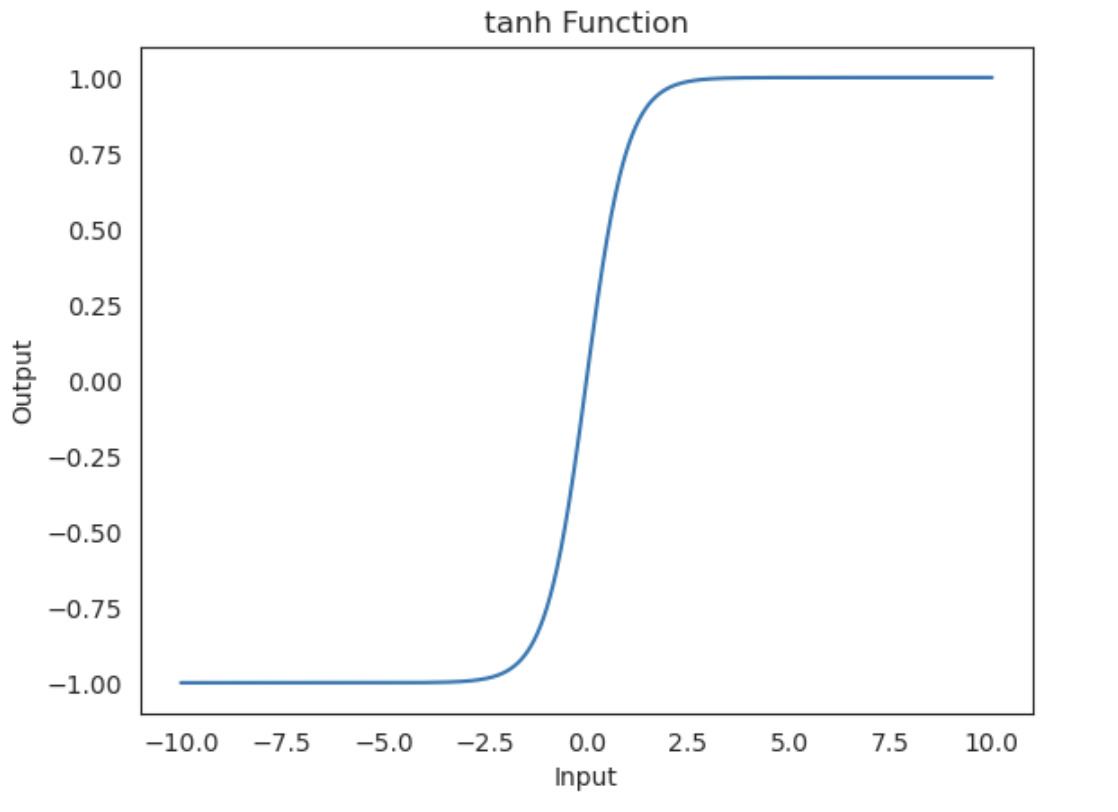 tanh function
tanh function
Hyperbolic Tangent 은 $y$값이 [-1, 1] 사이에서 정의된다고 했다. 다시 말해 셀의 출력값이 항상 일정 범위값( [-1,1] )으로 제한(가중치, 편향 더하는 것은 일단 제외) 된다는 것이다. 따라서 한정된 좁은 범위에 출력값들이 맵핑되는데, 이는 결국 입력값의 정보는 대부분 소실된 채 일부 특징만 정제 되어 출력되고 다음 레이어로 forward 됨을 의미한다. 그래프를 한 번 살펴보자. 특히 Inputs 값이 2.5 이상인 경우부터는 출력값이 거의 1에 수렴해 그 차이를 직관적으로 파악하기 힘들다. 이러한 활성함수가 수십개, 수백개 쌓인다면 결국 원본 정보는 매우 흐려지고 뭉개져서 다른 인스턴스와 구별이 힘들어 질 것이다.
🔬 3) 디코더가 가장 마지막 단어만 열심히 보고 denoising 수행 (Seq2Seq with Bi-Directional RNN)
“쓰다” ($t_7$)라는 단어의 뜻을 이해하려면 “돈을”, “모자를”, “맛이”, “글을”($t_1$)과 같이 멀리 있는 앞 단어를 봐야 알 수 있는데, $h_7$ 에는 $t_1$이 흐려진 채로 들어가 있어서 $t_7$의 제대로 된 의미를 포착하지 못한다. 심지어 언어가 영어라면 뒤를 봐야 정확한 문맥을 알 수 있는데 Vanilla RNN은 단방향으로만 학습을 하게 되어 문장의 뒷부분 문맥은 반영조차(뒤에 위치한 목적어에 따라서 쓰다라는 단어의 뉘앙스는 달라짐) 할 수 없다. 그래서 Bi-directional RNN 써야하는데, 이것도 역시도 여전히 “거리”에 영향 받는다는 건 변하지 않기 때문에 근본적인 해결책이라 볼 수 없다.
한편, 디코더의 Next Token Prediction 성능은 무조건 인코더로부터 받는 Context Vector의 품질에 따라 좌지우지 된다. 그러나 Recurrent 구조의 인코더로부터 나온 Context Vector는 앞서 서술한 것처럼 좋은 품질(뒤쪽 단어가 상대적으로 선명함)이 아니다. 따라서 디코더의 번역(다음 단어 예측) 성능 역시 좋을리가 없다.
결국 Recurrent 구조 자체에 명확한 한계가 존재하여 인간이 자연어를 사용하고 이해하는 맥락과 다른 방식으로 동작햐게 되었다. LSTM, GRU의 제안으로 어느 정도 문제를 완화 시켰으나, 앞에서 서술했듯이 태생이 Recurrent Structure을 가지기 때문에 근본적인 해결책이 되지는 못했다. 그렇다면 이제 Transformer가 어떻게 위에 서술한 3가지 문제를 해결하고 현재의 위상을 갖게 되었는지 알아보자.
🌟 Modeling
앞서 Recurrent 구조의 Vanishing Gradient 을 설명하면서 시점에 따라 정보를 소실하게 되는 현상은 인간의 자연어 이해 방식이 아니라는 점을 언급한 적 있다. 따라서 Transformer는 최대한 인간의 자연어 이해 방식을 수학적으로 모델링 하는 것에 초점을 맞췄다. 우리가 쓰여진 글을 이해하기 위해 하는 행동들을 떠올려 보자. “Apple”이란 단어가 사과를 말하는 것인지, 브랜드 애플을 지칭하는 것인지 파악하기 위해 같은 문장에 속한 주변 단어를 살피기도 하고 그래도 파악하기 힘들다면 앞뒤 문장, 나아가 문서 전체 레벨에서 맥락을 파악하기 위해 노력한다. Transformer 연구진은 바로 이 과정에 주목했으며 이것을 모델링하여 그 유명한 Self-Attention을 고안해낸다.
다시 말해 Self-Attention은 토큰의 의미를 이해하기 위해 전체 입력 시퀀스 중에서 어떤 단어에 주목해야할지를 수학적으로 표현한 것이라 볼 수 있다. 좀 더 구체적으로는 시퀀스에 속한 여러 토큰 벡터(행백터)를 임베딩 공간 어디에 배치할 것인가에 대해 훈련하는 행위다.
그렇다면 이제부터 Transformer 가 어떤 아이데이션을 통해 기존 순환 신경망 모델의 단점을 해결하고 딥러닝계의 G.O.A.T 자리를 차지했는지 알아보자. 모델은 크게 인코더와 디코더 부분으로 나뉘는데, 하는 역할과 미세한 구조상의 차이만 있을뿐 두 모듈 모두 Self-Attention이 제일 중요하다는 본질은 변하지 않는다. 따라서 Input Embedding부터 차례대로 살펴보되, Self-Attention 은 특별히 사용된 하위 블럭 단위를 빠짐 없이, 세세하게 살펴볼 것이다.
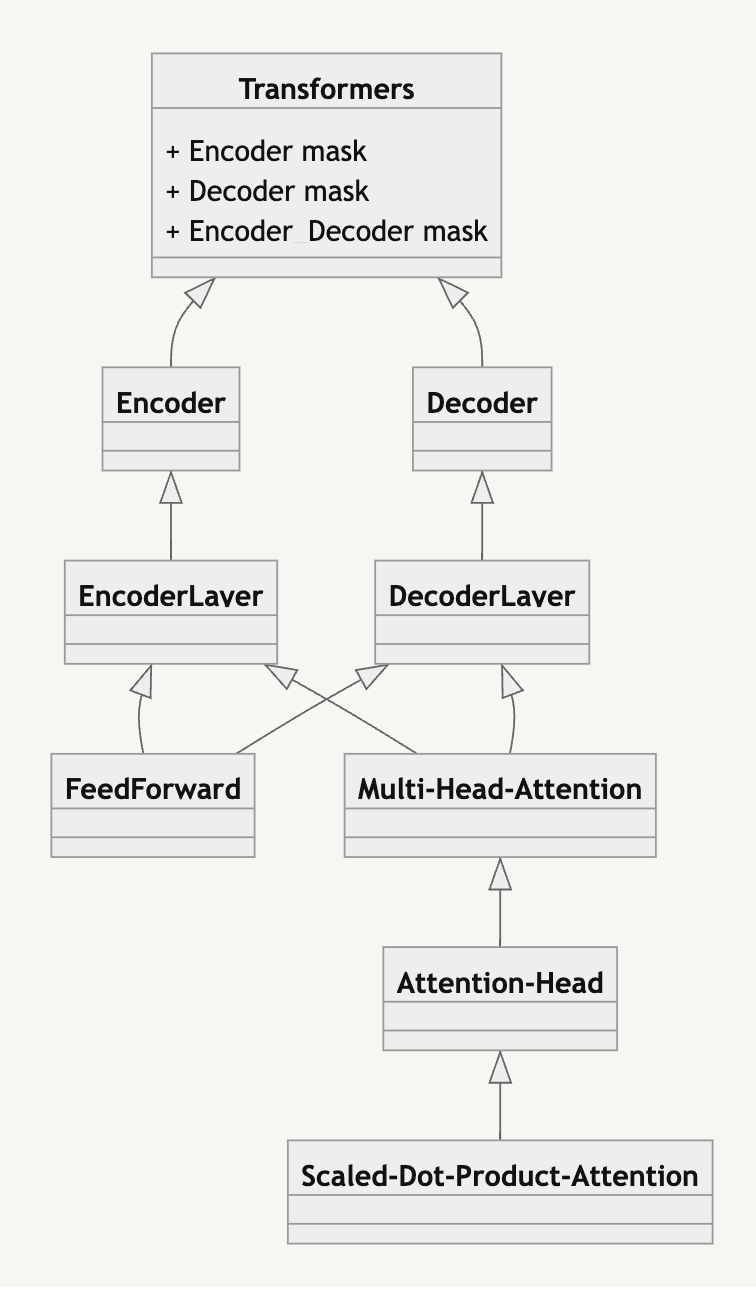 Class Diagram
Class Diagram
이렇게 하위 모듈에 대한 설명부터 쌓아 나가 마지막에는 실제 구현 코드와 함께 전체적인 구조 측면에서도 모델을 해석해볼 것이다. 끝까지 포스팅을 읽어주시길 바란다.
🔬 Input Embedding
\[X_E \in R^{B * S_E * V_E} \\
X_D \in R^{B * S_D * V_D}\]
Transformer는 인코더와 디코더로 이뤄진 seq2seq 구조를 가지고 있다. 즉, 대상 언어를 타겟 언어로 번역하는데 목적을 두고 있기 때문에 입력으로 대상 언어 시퀀스와 타겟 언어 시퀀스 모두 필요하다. $X_E$는 인코더의 입력 행렬을 나타내고, $X_D$는 디코더의 입력 행렬을 의미한다. 이 때, $B$는 batch size, $S$는 max_seq, $V$는 개별 모듈이 가진 Vocab의 사이즈를 가리킨다. 위 수식은 사실 논문에 입력에 대한 수식이 따로 서술 되어 있지 않아, 필자가 직접 만든 것이다. 앞으로도 해당 기호를 이용해 수식을 표현할 예정이니 참고 바란다.
이렇게 정의된 입력값을 개별 모듈의 임베딩 레이어에 통과 시킨 결과물이 바로 Input Embedding이 된다. $d$는 Transformer 모델의 은닉층의 크기를 의미한다. 따라서 Position Embedding 과 더해지기 전, 임베딩 레이어를 통과한 Input Embedding의 모양은 아래 수식과 같다.
그렇다면 실제 구현은 어떻게 할까?? Transformer 의 Input Embedding은 nn.Embedding으로 레이어를 정의해 사용한다. nn.Linear도 있는데 왜 굳이 nn.Embedding을 사용하는 것일까??
자연어 처리에서 입력 임베딩을 만들때는 모델의 토크나이저에 의해 사전 정의된 vocab의 사이즈가 입력 시퀀스에 속한 토큰 개수보다 훨씬 크기 때문에 데이터 룩업 테이블 방식의 nn.Embedding 을 사용하게 된다. 이게 무슨 말이냐면, 토크나이저에 의해 사전에 정의된 vocab 전체가 nn.Embedding(vocab_size, dim_model)로 투영 되어 가로는 vocab 사이즈, 세로는 모델의 차원 크기에 해당하는 룩업 테이블이 생성되고, 내가 입력한 토큰들은 전체 vocab의 일부분일테니 전체 임베딩 룩업 테이블에서 내가 임베딩하고 싶은 토큰들의 인덱스만 알아낸다는 것이다. 그래서 nn.Embedding 은 레이어에 정의된 차원과 실제 입력 데이터의 차원이 맞지 않아도 함수가 동작하게 된다. nn.Linear 와 입력 차원에 대한 조건 빼고는 동일한 동작을 수행하기 때문에 사전 정의된 vocab 사이즈와 입력 시퀀스의 토큰 개수가 같다면 nn.Linear를 사용해도 무방하다.
# Input Embedding Example
class Transformer(nn.Module):
def __init__(
self,
enc_vocab_size: int,
dec_vocab_size: int,
max_seq: int = 512,
enc_N: int = 6,
dec_N: int = 6,
dim_model: int = 512, # latent vector space
num_heads: int = 8,
dim_ffn: int = 2048,
dropout: float = 0.1
) -> None:
super(Transformer, self).__init__()
self.enc_input_embedding = nn.Embedding(enc_vocab_size, dim_model) # Encoder Input Embedding Layer
self.dec_input_embedding = nn.Embedding(dec_vocab_size, dim_model) # Decoder Input Embedding Layer
def forward(self, enc_inputs: Tensor, dec_inputs: Tensor, enc_pad_index: int, dec_pad_index: int) -> tuple[Tensor, Tensor, Tensor, Tensor]:
enc_x, dec_x = self.enc_input_embedding(enc_inputs), self.dec_input_embedding(dec_inputs)
위의 예시 코드를 함께 살펴보자. __init__ 의 self.enc_input_embedding, self._dec_input_embedding이 바로 $W_E, W_D$에 대응된다. 한편 forward 메서드에 정의된 enc_x, dec_x 는 임베딩 레이어를 거치고 나온 $X_E, X_D$에 해당된다.
한편, $X_E, X_D$은 각각 인코더, 디코더 모듈로 흘러 들어가 Absolute Position Embedding과 더해진(행렬 합) 뒤, 개별 모듈의 입력값으로 활용된다.
🔢 Absolute Position Embedding(Encoding)
입력 시퀀스에 위치 정보를 맵핑해주는 역할을 한다. 필자는 개인적으로 Transformer에서 가장 중요한 요소를 뽑으라고 하면 세 손가락 안에 들어가는 파트라고 생각한다. 다음 파트에서 자세히 기술하겠지만, Self-Attention(내적)은 입력 시퀀스를 병렬로 한꺼번에 처리할 수 있다는 장점을 갖고 있지만, 그 자체로는 토큰의 위치 정보를 인코딩할 수 없다. 우리가 따로 위치 정보를 알려주지 않는 이상 쿼리 행렬의 2번째 행벡터가 입력 시퀀스에서 몇 번째 위치한 토큰인지 모델은 알 길이 없다.
그런데, 텍스트는 Permutation Equivariant한 Bias 가 있기 때문에 토큰의 위치 정보는 NLP에서 매우 중요한 요소로 꼽힌다. 직관적으로도 토큰의 순서는 시퀀스가 내포하는 의미에 지대한 영향을 끼친다는 것을 알 수 있다. 예를 들어 “철수는 영희를 좋아한다”라는 문장과 “영희는 철수를 좋아한다”라는 문장의 의미가 같은가 생각해보자. 주어와 목적어 위치가 바뀌면서 정반대의 뜻이 되어버린다.

따라서 저자는 입력 입베딩에 위치 정보를 추가하고자 Position Encoding 을 제안한다. 사실 Position Encoding 은 여러 단점 때문에 후대 Transformer 파생 모델에서는 잘 사용되지 않는 추세다. 대신 모델이 학습을 통해 최적값을 찾아주는 Position Embedding 방식을 대부분 차용하고 있다. 필자 역시 Position Embedding 을 사용해 위치 임베딩을 구현했기 때문에 원리와 단점에 대해서만 간단히 소개하고 넘어가려 한다. 또한 저자 역시 논문에서 두 방식 중 어느 것을 써도 비슷한 성능을 보여준다고 언급하고 있다.
원리는 매우 간단하다. 사인함수와 코사인 함수의 주기성을 이용해 개별 인덱스의 행벡터 값을 표현하는 것이다. 행벡터의 원소 중에서 짝수번째 인덱스에 위치한 원소는 (짝수번째 열벡터) \(sin(pos/\overset{}{10000_{}^{2i/dmodel}})\) 의 함숫값을 이용해 채워넣고, 홀수번째 원소는 \(cos(pos/\overset{}{10000_{}^{2i/dmodel}})\)를 이용해 채워넣는다.
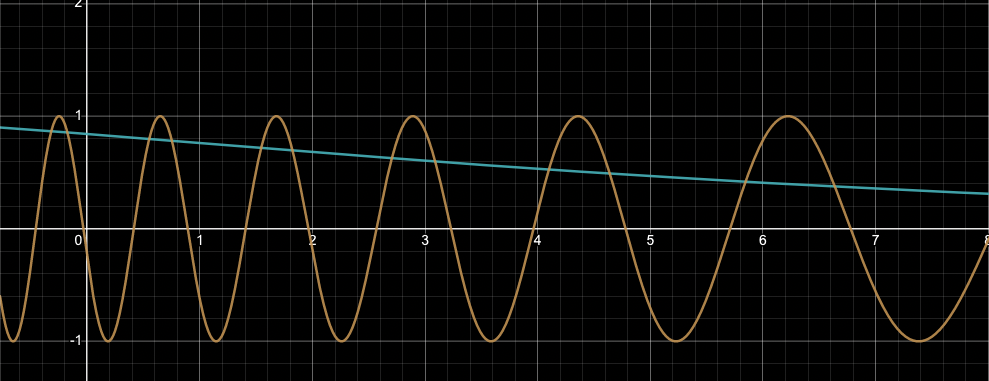 periodic function graph
periodic function graph
초록색 그래프는 \(sin(pos/\overset{}{10000_{}^{2i/dmodel}})\), 주황색 그래프는 \(cos(pos/\overset{}{10000_{}^{2i/dmodel}})\)를 시각화했다. 지면의 제한으로 max_seq=512 만큼의 변화량을 담지는 못했지만, x축이 커질수록 두 함수 모두 진동 주기가 조금씩 커지는 양상을 보여준다. 따라서 개별 인덱스(행벡터)를 중복되는 값 없이 표현하는 것이 가능하다고 저자는 주장한다.
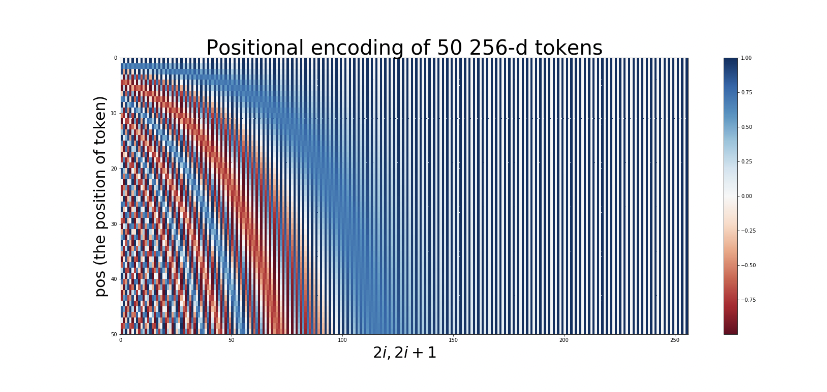
위 그림은 토큰 50개, 은닉층이 256차원으로 구성된 시퀀스에 대해 Positional Encoding한 결과를 시각화한 자료다. 그래프의 $x$축은 행벡터의 원소이자 Transformer의 은닉 벡터 차원을 가리키고, $y$축은 시퀀스의 인덱스(행벡터)를 의미한다. 육안으로 정확하게 차이를 인식하기 쉽지는 않지만, 행벡터가 모두 유니크하게 표현된다는 사실(직접 실수값을 확인해보면 정말 미세한 차이지만 개별 토큰의 희소성이 보장)을 알 수 있다. 작은 차이를 시각화 자료로 파악하기는 쉽지 않기 때문에 진짜 그런가 궁금하신 분들은 직접 실수값을 구해보는 것을 추천드린다.
여기서 행벡터의 희소성이란 개별 행벡터 원소의 희소성을 말하는게 아니다. 0번 토큰, 4번 토큰, 9번 토큰의 행벡터 1번째 원소의 값은 같을 수 있다. 하지만 진동 주기가 갈수록 커지는 주기함수를 사용하기 때문에 다른 원소(차원)값은 다를 것이라 기대할 수 있는데, 바로 이것을 행벡터의 희소성이라고 정의하는 것이다. 만약 1번 토큰과 2번 토큰의 모든 행벡터 원소값이 같다면 그것은 희소성 원칙에 위배되는 상황이다.

 Compare Performance between Encoding and Embedding
Compare Performance between Encoding and Embedding
비록 개별 행벡터의 희소성이 보장된다고 해도 Position Encoding은 not trainable해서 static하다는 단점이 있다. 모든 배치의 시퀀스가 동일한 위치 정보값을 갖게 된다는 것이다. 512개의 토큰으로 구성된 시퀀스 A와 B가 있다고 가정해보자. 이 때 시퀀스 A는 문장 5개로 구성 되어 있고, B는 문장 12개로 만들어졌다. 두 시퀀스의 11번째 토큰의 문장 성분은 과연 같을까?? 아마도 대부분의 경우에 다를 것이다. 텍스트 데이터에서 순서 정보가 중요한 이유 중 하나는 바로 syntactical 한 정보를 포착하기 위함이다. Position Encoding은 static 하기 때문에 이러한 타입의 정보를 인코딩 하기 쉽지 않다. 그래서 좀 더 풍부한 표현을 담을 수 있는 Position Embedding을 사용하는 것이 최근 추세다.
✏️ Position Embedding
그렇다면 이제 Position Embedding에 대해 알아보자. Position Embedding 은 Input Embedding을 정의한 방식과 거의 유사하다. 먼저 입력값과 weight 의 모양부터 확인해보자.
$P_E, P_D$는 개별 모듈의 위치 임베딩 레이어 입력을 가리키며, $W_{P_E}, W_{P_D}$가 개별 모듈의 위치 임베딩 레이어가 된다. 이제 이것을 코드로 어떻게 구현하는지 살펴보자.
# Absolute Position Embedding Example
class Encoder(nn.Module):
"""
In this class, encode input sequence and then we stack N EncoderLayer
First, we define "positional embedding" and then add to input embedding for making "word embedding"
Second, forward "word embedding" to N EncoderLayer and then get output embedding
In official paper, they use positional encoding, which is base on sinusoidal function(fixed, not learnable)
But we use "positional embedding" which is learnable from training
Args:
max_seq: maximum sequence length, default 512 from official paper
N: number of EncoderLayer, default 6 for base model
"""
def __init__(self, max_seq: 512, N: int = 6, dim_model: int = 512, num_heads: int = 8, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(Encoder, self).__init__()
self.max_seq = max_seq
self.scale = torch.sqrt(torch.Tensor(dim_model)) # scale factor for input embedding from official paper
self.positional_embedding = nn.Embedding(max_seq, dim_model) # add 1 for cls token
... 중략 ...
def forward(self, inputs: Tensor, mask: Tensor) -> tuple[Tensor, Tensor]:
"""
inputs: embedding from input sequence, shape => [BS, SEQ_LEN, DIM_MODEL]
mask: mask for Encoder padded token for speeding up to calculate attention score
"""
layer_output = []
pos_x = torch.arange(self.max_seq).repeat(inputs.shape[0]).to(inputs)
x = self.dropout(
self.scale * inputs + self.positional_embedding(pos_x) # layernorm 적용하고
)
... 중략 ...
위 코드는 Transformer의 인코더 모듈을 구현한 것이다. 그래서 forward 메서드의 pos_x 가 바로 $P_E$가 되며, __init__의 self.positional_embedding이 바로 $W_{P_E}$에 대응된다. 이렇게 정의한 Position Embedding은 Input Embedding과 더해서 Word Embedding 을 만든다. Word Embedding 은 다시 개별 모듈의 linear projection 레이어에 대한 입력 $X$로 사용 된다.
한편, Input Embedding 과 Position Embedding을 더한다는 것에 주목해보자. 필자는 본 논문을 보며 가장 의문이 들었던 부분이다. 도대체 왜 완전히 서로 다른 출처에서 만들어진 행렬 두개를 concat 하지 않고 더해서 사용했을까?? concat을 이용하면 Input과 Position 정보를 서로 다른 차원에 두고 학습하는게 가능했을텐데 말이다.
🤔 Why Sum instead of Concatenate
행렬합을 사용하는 이유에 대해 저자가 특별히 언급하지는 않아서 때문에 정확한 의도를 알 수 없지만, 추측하건데 blessing of dimensionality 효과를 의도했지 않았나 싶다. blessing of dimensionality 란, 고차원 공간에서 무작위로 서로 다른 벡터 두개를 선택하면 두 벡터는 거의 대부분 approximate orthogonality를 갖는 현상을 설명하는 용어다. 무조건 성립하는 성질은 아니고 확률론적인 접근이라는 것을 명심하자. 아무튼 직교하는 두 벡터는 내적값이 0에 수렴한다. 즉, 두 벡터는 서로에게 영향을 미치지 못한다는 것이다. 이것은 전체 모델의 hidden states space 에서 Input Embedding 과 Position Embedding 역시 개별 벡터가 span 하는 부분 공간 끼리는 서로 직교할 가능성이 매우 높다는 것을 의미한다. 따라서 서로 다른 출처를 통해 만들어진 두 행렬을 더해도 서로에게 영향을 미치지 못할 것이고 그로 인해 모델이 Input과 Position 정보를 따로 잘 학습할 수 있을 것이라 기대해볼 수 있다. 가정대로만 된다면, concat 을 사용해 모델의 hidden states space 를 늘려 Computational Overhead 를 유발하는 것보다 훨씬 효율적이라고 볼 수 있겠다.
한편 blessing of dimensionality에 대한 설명과 증명은 꽤나 많은 내용이 필요해 여기서는 자세히 다루지 않고, 다른 포스트에서 따로 다루겠다. 관련하여 좋은 내용을 담고 있는 글의 링크를 같이 첨부했으니 읽어보실 것을 권한다(링크1, 링크2).
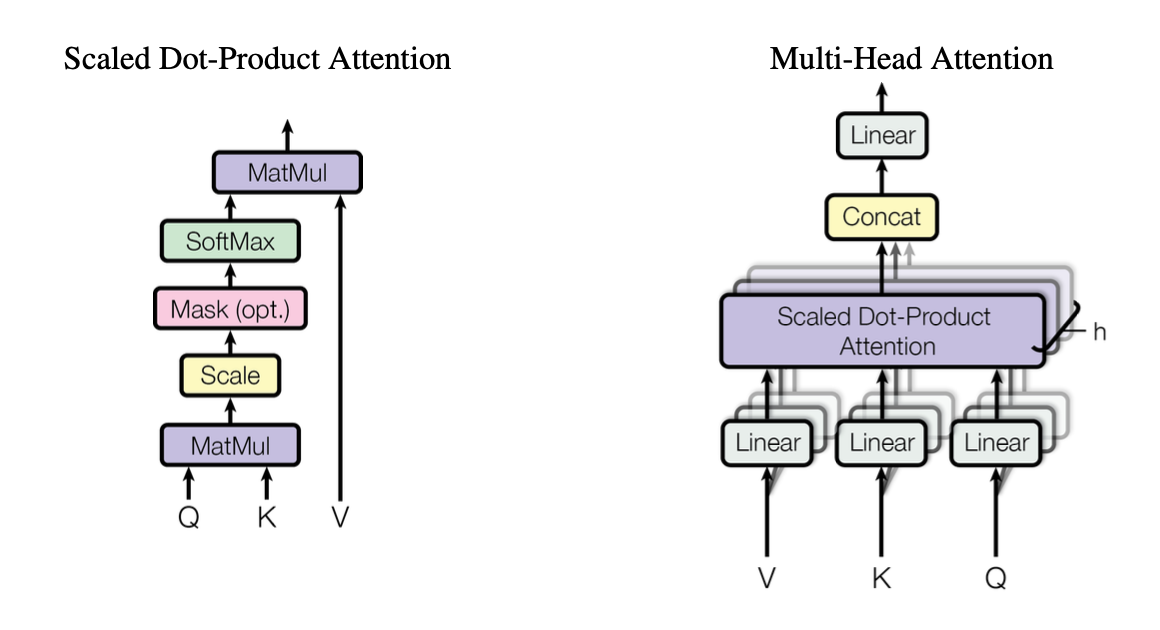
🚀 Self-Attention with linear projection
왜 이름이 self-attention일까 먼저 고민해보자. 사실 attention 개념은 본 논문이 발표되기 이전부터 사용되던 개념이다. attention은 seq2seq 구조에서 처음 나왔는데, seq2seq 은 번역 성능을 높이는 것을 목적으로 고안된 구조라서, 목표인 디코더의 hidden_states 값을 쿼리로, 인코더의 hidden_states를 키, 벨류의 출처로 사용했다. 즉, 서로 다른 출처에서 나온 hidden_states 을 사용해 내적 연산을 수행했던 것이다. 이런 개념에 이제 “self" 라는 이름이 붙었다. 결국 같은 출처에서 나온 hidden_states 를 내적하겠다는 의미를 내포하고 있는 것이다. 내적은 두 벡터의 “닮은 정도” 를 수학적으로 계산한다. 따라서 self-attention 이란 간단하게, 같은 출처에서 만들어진 $Q$(쿼리), $K$(키), $V$(벨류)가 서로 얼마나 닮았는지 계산해보겠다는 것이다.
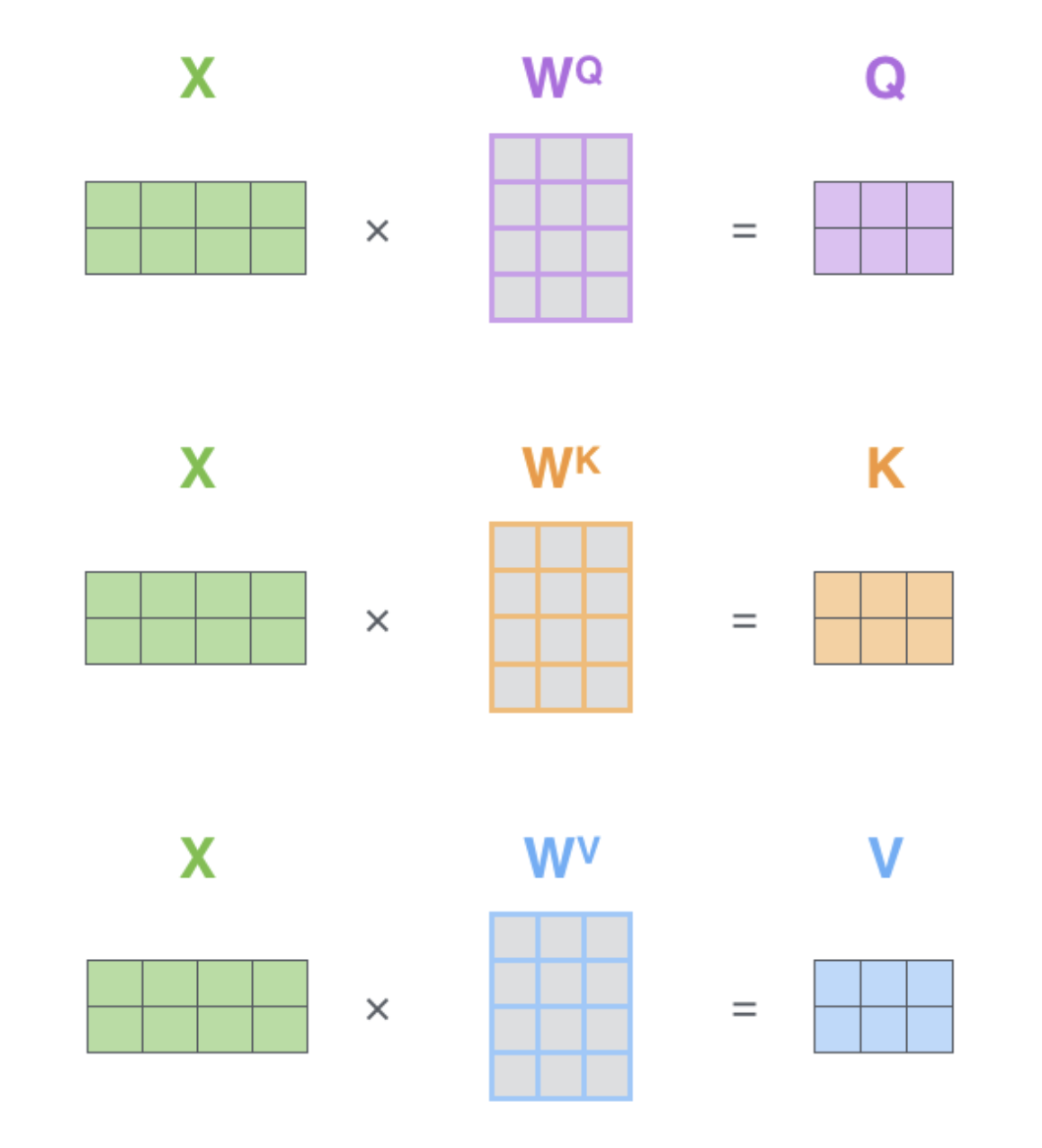 self-attention with linear projection
self-attention with linear projection
그렇다면 이제 $Q$(쿼리), $K$(키), $V$(벨류)의 정체, 같은 출처에서 나왔다는 말의 의미 그리고 입력 행렬 $X$를 linear projection 하여 $Q$(쿼리), $K$(키), $V$(벨류) 행렬을 만드는 이유를 구체적인 예시를 통해 이해해보자. 추가로 $Q$(쿼리), $K$(키), $V$(벨류) 개념은 Information Retrieval에서 먼저 파생된 개념이라서 예시 역시 정보 검색과 관련된 것으로 준비했다.
당신이 만약 “에어컨 필터 청소하는 방법”이 궁금해 구글에 검색하는 상황이라고 가정해보겠다. 목표는 가장 빠르고 정확하게 내가 원하는 필터 청소 방법에 대한 지식을 획득하는 것이다. 그렇다면 당신은 뭐라고 구글 검색창에 검색할 것인가?? 이것이 바로 $Q$(쿼리)에 해당한다. 당신은 검색창에 “에어컨 필터 청소하는 방법”을 입력해 검색 결과를 반환 받았다. 반환 받은 결과물의 집합이 바로 $K$(키)가 된다. 당신은 총 100개의 블로그 게시물을 키 값으로 받았다. 그래서 당신이 사용하는 삼성 무풍 에어컨의 필터 청소법이 정확히 적힌 게시물을 찾기 위해 하나 하나 링크를 타고 들어가 보았다. 하지만 정확하게 원하는 정보가 없어서 계속 찾다보니 결국 4페이지 쯤에서 원하던 정보가 담긴 게시물을 찾을 수 있었다. 이렇게 내가 원하는 정보인지 아닌지 대조하는 과정이 바로 $Q$(쿼리)와 $K$(키) 행렬을 내적하는 행위가 된다. 곧바로 에어컨 청소를 하려고 보니, 방법을 까먹어서 매년 여름마다 검색을 해야할 것 같아 해당 게시물을 북마크에 저장해두었다. 여기서 북마크가 바로 $V$(벨류) 행렬이 된다.
이 모든 과정에 10분이 걸렸다. 겨우 필터 청소 방법을 찾는데 10분이라니 당신은 자존심이 상했다. 더 빨리 원하는 정보(손실 함수 최적화)를 찾을 수 있는 방법이 없을까 고민해보다가 당신이 사용하는 에어컨 브랜드명(삼성 Bespoke 에어컨)을 검색어에 추가하기로 했다. 그랬더니 1페이지 최하단에서 아까 4페이지에서 찾은 정보를 곧바로 찾을 수 있었다. 그 덕분에 시간을 10분에서 1분 30초로 단축시킬 수 있었다. 이렇게 검색 시간을 단축(손실 줄이기)하기 위해 더 나은 검색 표현을 고민하고 수정하는 행위가 바로 입력 $X$에 $W_{Q}$를 곱해 행렬 $Q$ 을 만드는 수식으로 표현된다.
1년 뒤 여름, 당신은 브라우저를 바꾼 탓에 북마크가 초기화 되어 다시 한 번 검색을 해야 했다. 하지만 여전히 검색어는 기억하고 있어서, 1년전 최적의 결과를 얻었던 그대로 다시 검색을 했다. 분명 똑같이 검색을 했는데 같은 결과가 1페이지 최상단에서 반환되고 있었다. 당신은 이게 어떻게 된 일인지 궁금해 포스트를 천천히 보던 중, 제목에 1년전에는 없던 삼성 Bespoke 에어컨 이라는 키워드가 포함 되어 있었다. 게시물의 주인장이 SEO 최적화를 위해 추가했던 것이었다. 덕분에 당신은 소요 시간을 1분 30초에서 20초로 줄일 수 있었다. 이런 상황이 바로 입력 $X$에 $W_{K}$를 곱해 행렬 $K$ 를 만드는 수식에 대응된다.
우리는 위 예시를 통해 원하는 정보를 빠르고 정확하게 찾는 행위란, 답변자가 이해하기 좋은 질문과 질문자의 질문 의도에 부합하는 좋은 답변으로 완성된다는 것을 알 수 있었다. 뿐만 아니라, 좋은 질문과 좋은 답변이라는 것은 처음부터 완성되는게 아니라 검색 시간을 단축하려는 끊임없는 노력을 통해 성취된다는 것 역시 깨우쳤다. 두가지 인사이트가 바로 linear projection으로 행렬 $Q, K,V$을 정의한 이유다. 내가 원하는 정보인지 아닌지 대조하는 내적 연산은 수행하는데 가중치 행렬이 필요 없기 때문에 손실함수의 오차 역전을 활용한 수치 최적화를 수행할 수 없다. 그래서 손실함수 미분에 의한 최적화가 가능하도록 linear projection matrix를 활용해 행렬 $Q, K,V$를 정의해준 것이다. 이렇게 하면 모델이 우리의 목적에 가장 적합한 질문과 답변을 알아서 표현 해줄 것이라 기대할 수 있게 된다. 한편, 같은 출처에서 나왔다는 말은 방금 예시에서 행렬 $Q, K,V$를 만드는데 동일하게 입력 $X$를 사용 것과 같은 상황을 의미한다.
이제 다시 자연어 처리 맥락으로 돌아와보자. Transformer 는 좋은 번역기를 만들기 위해 고안된 seq2seq 구조의 모델이다. 즉, 빠르고 정확하게 대상 언어에서 타겟 언어로 번역하는 것에 목표를 두고 만들어졌다는 것이다. 번역을 잘하기 위해서는 어떻게 해야 할까?? 1) 대상 언어로 쓰인 시퀀스의 의미를 정확하게 파악해야 하고, 2) 파악한 의미와 가장 유사한 시퀀스를 타겟 언어로 만들어 내야 한다. 그래서 1번의 역할은 Encoder가 그리고 2번은 Decoder가 맡게 된다. 인코더는 결국 (번역하는데 적합한 형태로) 대상 언어 시퀀스의 의미를 정확히 이해하는 방향(숫자로 표현, 임베딩 추출)으로 학습을 수행하게 되며, 디코더는 인코더의 학습 결과와 가장 유사한 문장을 타겟 언어로 생성해내는 과정을 배우게 된다. 따라서 인코더는 대상 언어를 출처로, 디코더는 타겟 언어를 출처로 행렬 $Q, K,V$를 만든다. 정확히 self 라는 단어를 이름에 갖다 붙인 의도와 일맥상통하는 모습이다.
결국 Transformer 의 성능을 좌지우지 하는 것은 누가 얼마나 더 linear projection weight을 잘 최적화 하는가에 달렸다고 볼 수 있다.
한편 필자는 처음 이 논문을 읽었을 때 linear projection 자체의 필요성은 공감했으나, 굳이 3개의 행렬로 나눠서 train 시켜야 하는 param 숫자를 늘리는 것보다는 weight share 하는 형태로 만드는게 더 효율적일 것 같다는 추측을 했었다.
그러나 이번 리뷰를 위해 다시 논문을 읽던 중, 좋은 질문을 하기 위한 노력과 좋은 답변을 하기 위한 노력, 그리고 필요한 정보를 정확히 추출해내는 행위를 각각 서로 다른 3개의 벡터로 표현했을 때 벡터들이 가지는 방향성이 서로 다를텐데 그것을 하나의 벡터로 표현하려면 모델이 학습을 하기 힘들 것 같다는 생각이 들었다. 방금 위에서 든 예시만 봐도 그렇다. 서로 다른 3개의 행위 사이의 최적 지점을 찾으라는 것과 마찬가진데 그런 스팟이 있다고 해도 언어 모델이 잘 찾을 수 있을까?? 인간도 찾기 힘든 것을 모델이 잘 찾을리가 없다.
📐 Scaled Dot-Product Attention
\[Attention(Q,K,V) = softmax(\frac{Q·K^T}{\sqrt{d_k}})V\]
이번에는 Self-Attention 의 두 번째 하위 블럭인 Scaled Dot-Product Attention 차례다. 사실 우리는 Linear Projection 파트에서 이미 우리도 모르게 Scaled Dot-Product Attention 에 대해 공부했다. 예시를 다시 한 번 상기시켜보자. 질의를 통해 얻은 결과 리스트(키)에서 내가 원하는 정보를 찾기 위해 쿼리와 키를 대조한다고 했던 것 기억나는가?? 바로 그 대조하는 행위를 수학적으로 모델링한 것이 바로 Scaled Dot-Product Attention 에 해당한다.
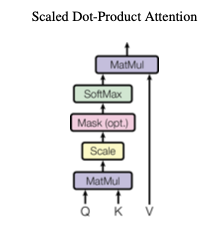
Scaled Dot-Product Attention 은 총 5단계를 거쳐 완성된다. 단계마다 어떤 연산을 왜 하는지 그리고 무슨 인사이트가 담겨 있는지 알아보자. 이 중에서 마스킹 단계는 인코더와 디코더의 동작을 자세히 알아야하기 때문에 전체적인 구조 관점에서 모델을 바라볼 때 함께 설명하도록 하겠다.
✖️ Stage 1. Q•K^T Dot-Product
인간은 문장이나 어떤 표현의 의미를 파악하는데 바로 주변 맥락을 참고하거나, 더 멀리 떨어진 곳의 단어•시퀀스를 이용하기도 한다. 즉, 주어진 시퀀스 내부의 모든 맥락을 이용해 특정 부분의 의미를 이해한다는 것이다. 그렇다고 모든 정보가 동일하게 특정 표현의 의미에 영향을 미치는 것은 또 아닌데, 수능 영어에 킬러 문항으로 등장하는 빈칸 채우기 문제를 어떻게 풀었나 떠올려보자. 디테일한 풀이 방식에는 사람마다 차이가 있겠지만, 일반적으로 지문은 모두 훑어 보되 빈칸에 들어갈 정답의 근거가 되는 특정 문장 혹은 표현 1~2개를 찾아내어 비슷한 의미를 지닌 선지를 골라 내는 방식을 사용한다. 다시 말해, 주어진 전체 단락에서 의미를 이해하는데 중요한 역할을 하는 표현이나 문장을 골라내어 중요도 만큼 가중치 를 주겠다는 것이다.
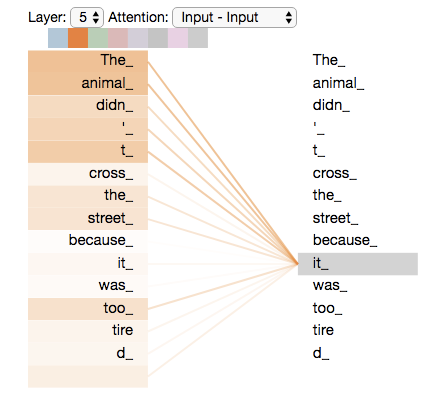 Q•K^T Dot Product Visualization
Q•K^T Dot Product Visualization
그렇다면 이것을 어떻게 수학적으로 모델링했을까?? 바로 행렬 $Q$와 $K^T$의 내적을 활용한다. 행렬 $Q$는 모델이 의미를 파악해야 하는 대상이 담겨 있고, 행렬 $K$에는 의미 파악에 필요한 단서들이 담겨있다. 내적은 두 벡터의 서로 “닮은 정도” 를 의미한다고 했다. “닮은 정도” 가 바로 중요도•가중치에 대응된다. 따라서 연산 결과는 전체 시퀀스에 속한 토큰들 사이의 “닮은 정도” 가 수치로 변환되어 행렬에 담긴다.
왜 내적 결과가 중요도와 같은 의미를 갖게 되는 것일까?? 아까 Input Embedding과 Position Embedding을 행렬합 하는 것에 대한 당위성을 설명하면서 고차원으로 갈수록 대부분의 벡터 쌍은 직교성을 갖게 된다고 언급한 바 있다. 그래서 두 벡터가 비슷한 방향성을 갖는다는 것 자체가 매우 드문일이다. 희귀하고 드문 사건은 그만큼 중요하다고 말할 수 있기 때문에 내적 결과를 중요도에 맵핑하는 것이다.
한편, 행렬 $Q,K$ 모두 차원이 [Batch, Max_Seq, Dim_Head] 인 텐서라서 내적한 결과의 모양은 [Batch, Max_Seq, Max_Seq] 이 될 것이다.
🔭 Stage 2. Scale
“I am dog” 라는 문장을 $Q•K^T$하면 위와 같은 3x3 짜리 행렬이 나올 것이다. 행렬을 행벡터로 바라보자. 행 사이의 값의 분포가 고르지 못하다는 것을 알 수 있다. 이렇게 분산이 큰 상태로 softmax 에 통과시키게 되면 역전파 과정에서 softmax 의 미분값이 줄어 들어 학습 속도가 느려지고 나아가 vanishing gradient 현상이 발생할 수 있다. 따라서 행벡터 사이의 분산을 줄여주기 위해서 Scale Factor 를 정의하게 된다. 그렇다면 어떤 Scale Factor 를 써야할까??
애초에 Dim Head 차원에 속한 값들의 분산이 큰 것도 문제가 되지만 이것은 Input Embedding이나 Position Embedding에 layernorm 을 적용하면 해결할 수 있기 때문에 논의 대상이 아니다. 그것보다는 내적 과정에 주목해보자. 우리는 내적을 하다보면 Dim Head의 차원이 커질수록 더해줘야 하는 스칼라 값의 개수가 늘어나게 된다는 사실을 알 수 있다. 만약 위에서 예시로 든 수식의 Dim Head가 64라고 가정해보자. 그럼 우리는 1행 1열의 값을 얻기 위해 64개의 스칼라 값을 더해줘야 한다. 만약 512차원이라면 512개로 불어난다. 더해줘야 하는 스칼라 값이 많아진다면 행벡터 끼리의 분산이 커질 우려가 있다. 따라서 차원 크기의 스케일에 따라 softmax의 미분값이 줄어드는 것을 방지하기 위해 $Q•K^T$결과에 $\sqrt{d_h}$를 나눠 준다.
여담으로 이러한 scale factor 의 존재 때문에 Self-Attention을 Scaled Dot-Product Attention 이라고 부르기도 한다.
🎭 Stage 3. masking
마스킹은 인코더 Input Padding, 디코더 Masked Multi-Head Attention, 인코더-디코더 Self-Attention 을 위해 필요한 계층이다. 뒤에 두개는 디코더의 동작을 알아야 이해가 가능하기 때문에 여기서는 인코더의 마스킹에 대해서만 알아보자.
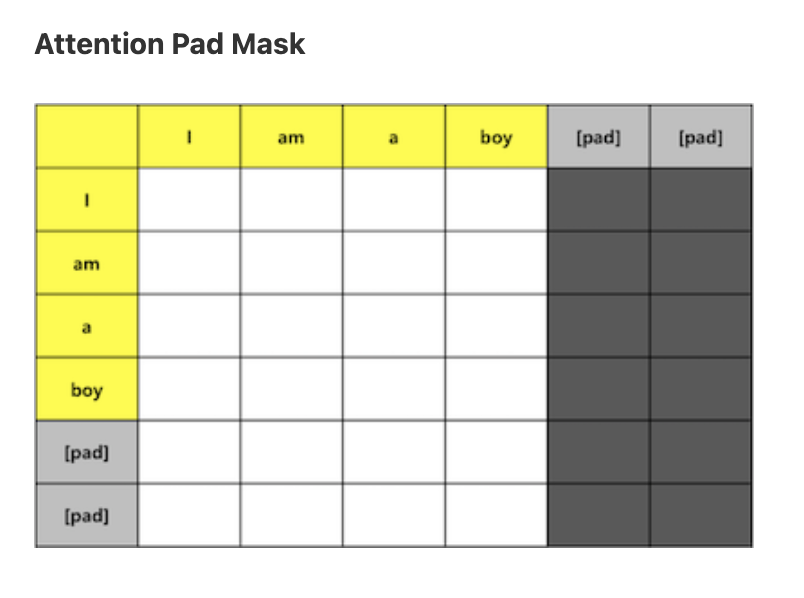
실제 텍스트 데이터는 배치된 시퀀스마다 그 길이가 제각각이다. 효율성을 위해 행렬을 사용하는 컴퓨터 연산 특성상 배치된 시퀀스의 길이가 모두 다르다면 연산을 진행할 수가 없다. 따라서 배치 내부의 모든 시퀀스의 길이를 통일해주는 작업을 하게 되는데, 이 때 기준 길이보다 짧은 시퀀스에 대해서는 0값을 채워넣는 padding 작업을 한다. 행렬 연산에는 꼭 필요했던 padding은 오히려 softmax 레이어를 계산할 때 방해가 된다. 따라서 모든 padding 값을 softmax의 확률 계산에서 완전히 제외시키기 위해 Input Embedding에서 padding token의 인덱스를 저장하고 해당되는 모든 원소를 -∞ 로 마스킹하는 과정이 필요하다.
이 때 마스킹 처리는 열벡터에만 적용한다. 그 이유는 바로 softmax 계산을 어차피 행벡터 방향으로만 할 것이기 때문이다. 행벡터 방향의 padding token에도 동일하게 마스킹 적용하는 것은 상관 없으나 열벡터와 행벡터 동시에 마스킹 적용하는 동작을 구현하는 것은 생각보다 많이 까다로우며, 나중에 손실값 계산하는 단계에서 ignore_index 옵션을 사용해 행벡터의 padding token을 무시하는 것이 훨씬 효율적이다. 한편, ignore_index 옵션은 nn.CrossEntropyLoss 에 매개변수로 구현 되어 있다.
📈 Stage 4. Softmax & Score•V
계산된 유사도(내적 결과, 중요도, 가중치), $\frac{Q•K^T}{\sqrt{d_h}}$는 이후에 행렬 $V$와 다시 곱해져 행벡터 $Z_n$(n번째 토큰)에서 토큰에 대한 어텐션 정도를 나타내는 가중치의 역할을 하게 된다. 그러나 계산된 유사도는 비정규화된 형태다. 수식에는 편의상 이미 softmax를 적용한 형태의 행렬을 적었지만, 실제로는 원소값의 분산이 너무 커서 가중치로는 쓰기 힘든 수준이다. 따라서 행벡터 단위로 softmax에 통과시켜 결과의 합이 1인 확률값으로 변환(정규화)해 행렬 $V$의 가중치로 사용한다.
이제 두번째 수식을 보자. $Score_{11}$에 해당하는 0.90가 행렬 $V$의 첫번째 행벡터와 곱해지고 있다. 행렬 $V$의 첫번째 행벡터는 토큰 “I” 를 512차원으로 표현한 것이다. 그 다음 $Score_{12}$는 행렬 $V$의 두번째 행벡터와, $Score_{13}$은 행렬 $V$의 세번째 행벡터와 각각 곱해진다.
이 행위의 의미는 무엇일까?? $Score_{11}$, $Score_{12}$, $Score_{13}$은 모두 첫번째 토큰인 “I”에 의미를 파악하는데 “I”, “am”, “dog”를 어느 정도로 어텐션해야 하는지, 즉 “I”의 의미를 표현하는데 세 토큰의 의미를 어느 정도 반영할지 수치로 표현한 것이다. 당연히 자기 자신인 “I”와 가중치(유사도, 중요도)가 가장 높기 때문에 행렬 $V$에서 “I” 에 해당하는 행벡터 가중치에 가장 큰 값이 들어간다고 생각해볼 수 있다. 이렇게 각 토큰마다 가중합을 반복해주면 최종적으로 “I”, “am”, “dog” 을 인코딩한 $Z_1, \ Z_2, \ Z_3$ 값을 얻을 수 있다.
👩💻 Implementation
이렇게 Scaled Dot-Product Attention 을 모두 살펴보았다. 해당 레이어는 모델이 손실값이 가장 작아지는 방향으로 최적화한 행렬 $Q, K, V$ 을 이용해, 토큰의 의미를 이해하는데 어떤 맥락과 표현에 좀 더 집중하고 덜 집중해야 하는지를 유사도를 기준으로 판단한다는 것을 꼭 기억하자. 그렇다면 실제 코드는 어떻게 작성 해야하는지 함께 알아보자. 상단의 class diagram 을 다시 한 번 보고 돌아오자.
# Pytorch Implementation of Scaled Dot-Product Self-Attention
def scaled_dot_product_attention(q: Tensor, k: Tensor, v: Tensor, dot_scale: Tensor, mask: Tensor = None) -> Tensor:
"""
Scaled Dot-Product Attention with Masking for Decoder
Args:
q: query matrix, shape (batch_size, seq_len, dim_head)
k: key matrix, shape (batch_size, seq_len, dim_head)
v: value matrix, shape (batch_size, seq_len, dim_head)
dot_scale: scale factor for Q•K^T result
mask: there are three types of mask, mask matrix shape must be same as single attention head
1) Encoder padded token
2) Decoder Masked-Self-Attention
3) Decoder's Encoder-Decoder Attention
Math:
A = softmax(q•k^t/sqrt(D_h)), SA(z) = Av
"""
attention_matrix = torch.matmul(q, k.transpose(-1, -2)) / dot_scale
if mask is not None:
attention_matrix = attention_matrix.masked_fill(mask == 0, float('-inf'))
attention_dist = F.softmax(attention_matrix, dim=-1)
attention_matrix = torch.matmul(attention_dist, v)
return attention_matrix
마스킹 옵션의 경우 주석에 정리된 3가지 상황 중에서 한 개 이상에 해당되면 실행되도록 코드를 작성했다. 3가지 상황과 구체적인 마스킹 방법에 대해서는 전체 모델 구조를 보는 때 소개하도록 하겠다.
한편, 인코더나 디코더나 모두 사용하는 입력과 마스킹 방식에 차이는 있지만, Scaled Dot-Product Attention 연산 자체는 동일한 것을 사용한다. 따라서 여러개의 인코더나 디코더 객체들 혹은 어텐션 해드 객체들이 모두 쉽게 연산에 접근할 수 있게 클래스 외부에 메서드 형태로 구현하게 되었다.
👩👩👧👦 Multi-Head Attention Block
지금까지 살펴본 Self-Attention의 동작은 모두 한 개의 Attention-Head에서 일어나는 일을 서술한 것이다. 사실 실제 모델에서는 같은 동작이 N-1개의 다른 해드에서 동시에 일어나는데, 이것이 바로 Multi-Head Attention이다.
Official Paper 기준으로 Transformer-base의 hidden states 차원은 512이다. 이것을 개당 64차원을 갖는 8개의 Attention-Head 로 쪼갠 뒤, 8개의 Attention-Head 에서 동시에 Self-Attention 을 수행한다. 이후 결과를 concat하여 다시 hidden states 를 512 로 만든 뒤, 여러 해드에서 만든 결과를 연결하고 섞어주기 위해 입출력 차원이 hidden states와 동일한 linear projection layer에 통과시킨다. 이것이 인코더(혹은 디코더) 블럭 한 개의 최종 Self-Attention 결과가 된다.
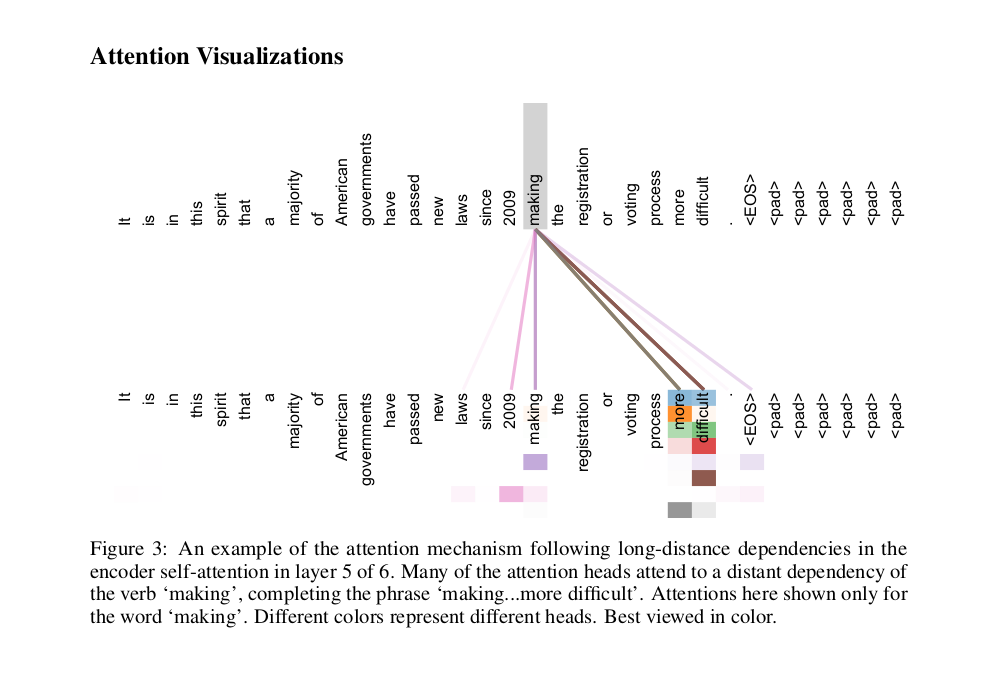 Multi-Head Attention Result Visualization
Multi-Head Attention Result Visualization
그럼 왜 이렇게 여러 해드를 사용했을까?? 바로 집단지성의 효과를 누리기 위함이다. 생각해보자. 책 하나를 읽어도 사람마다 정말 다양한 해석이 나온다. 모델도 마찬가지다. 여러 해드를 사용해서 좀 더 다양하고 풍부한 의미를 임베딩에 담고 싶었던 것이다. Kaggle을 해보신 독자라면, 여러 전략을 사용해 여러 개의 결과를 도출한 뒤, 마지막에 모두 앙상블하면 전략 하나 하나의 결과보다 더 높은 성적을 얻어본 경험이 있을 것이다. 이것도 비슷한 효과를 의도했다고 생각한다. Vision에서 Conv Filter를 여러 종류 사용해 다양한 Feature Map을 추출하는 것도 비슷한 현상이라 볼 수 있겠다.
위 그림은 저자가 제시한 Multi-Head Attention의 시각화 결과다. 중간에 있는 여러 색깔의 띠는 개별 해드가 어텐션하는 방향을 가리킨다. 토큰 “making” 에 대해서 해드들이 서로 다른 토큰에 어텐션하고 있다.
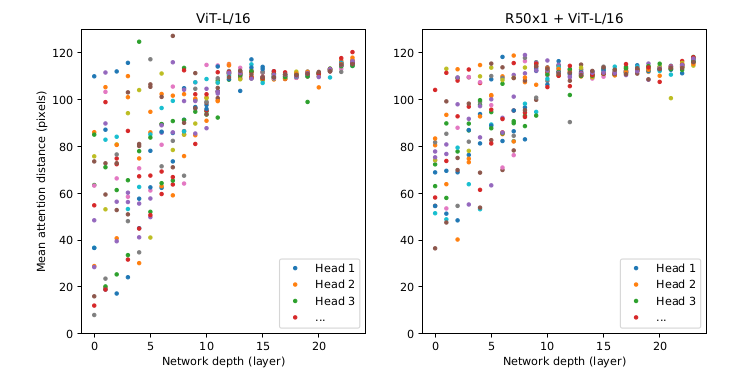 ViT Multi-Head Attention Result Visualization
ViT Multi-Head Attention Result Visualization
위 그림은 Vision Transformer 논문에서 발췌한 그림(그림의 자세한 의미는 여기서)이다. 역시 마찬가지로 모델의 초반부 인코더에 속한 Multi-Head들이 서로 다양한 토큰에 어텐션을 하고 있음을 알 수 있다. 추가로 후반으로 갈수록 점점 Attention Distance 가 일정한 수준에 수렴하는 모습을 볼 수 있는데, 이것을 레이어를 통과할수록 개별 해드가 자신이 어떤 토큰에 주의를 기울여야할지 구체적으로 알아가는 과정이라고 해석할 수 있다. 초반부에는 어찌할 바를 몰라서 이토큰 저토큰에 죄다 어텐션하는 것이다.
그래서 Transformer는 Bottom Layer에서는 Global하고 General한 정보를 포착하고, Output과 가까운 Top Layer에서는 Local하고 Specific한 정보를 포착한다.
👩💻 Implementation
이제 구현을 실제로 구현을 해보자. 역시 구현은 파이토치로 진행했다.
# Pytorch Implemenation of Single Attention Head
class AttentionHead(nn.Module):
"""
In this class, we implement workflow of single attention head
Args:
dim_model: dimension of model's latent vector space, default 512 from official paper
dim_head: dimension of each attention head, default 64 from official paper (512 / 8)
dropout: dropout rate, default 0.1
Math:
[q,k,v]=z•U_qkv, A = softmax(q•k^t/sqrt(D_h)), SA(z) = Av
"""
def __init__(self, dim_model: int = 512, dim_head: int = 64, dropout: float = 0.1) -> None:
super(AttentionHead, self).__init__()
self.dim_model = dim_model
self.dim_head = dim_head # 512 / 8 = 64
self.dropout = dropout
self.dot_scale = torch.sqrt(torch.tensor(self.dim_head))
self.fc_q = nn.Linear(self.dim_model, self.dim_head) # Linear Projection for Query Matrix
self.fc_k = nn.Linear(self.dim_model, self.dim_head) # Linear Projection for Key Matrix
self.fc_v = nn.Linear(self.dim_model, self.dim_head) # Linear Projection for Value Matrix
def forward(self, x: Tensor, mask: Tensor, enc_output: Tensor = None) -> Tensor:
q, k, v = self.fc_q(x), self.fc_k(x), self.fc_v(x) # x is previous layer's output
if enc_output is not None:
""" For encoder-decoder self-attention """
k = self.fc_k(enc_output)
v = self.fc_v(enc_output)
attention_matrix = scaled_dot_product_attention(q, k, v, self.dot_scale, mask=mask)
return attention_matrix
똑같은 Attention-Head를 N개 사용하기 때문에 먼저 Single Attention Head의 동작을 따로 객체로 만들었다. 이렇게 하면 MultiHeadAttention 객체에서 nn.ModuleList 를 사용해 N개의 해드를 이어붙일 수 있어서 구현이 훨씬 간편해지기 때문이다. Single Attention Head 객체가 하는 일은 다음과 같다.
- 1) Linear Projection by Dimension of Single Attention Head
- 2) Maksing
- 3) Scaled Dot-Product Attention
한편, 여러 Transformer 구현 Git Repo를 살펴보면 구현 방법은 크게 필자처럼 Single Attention Head를 추상화하거나 MultiHeadAttention 객체 하나에 모든 동작을 때려넣는 방식으로 나뉘는 것 같다. 사실 구현에 정답은 없지만 개인적으로 후자의 방식은 비효율적이라 생각한다. 저렇게 구현하면 3*N개의 linear projector를 클래스 __init__ 에 만들고 관리해줘야 하는데 쉽지 않을 것이다. 물론 3개의 linear projector 만 초기화해서 사용하고 대신 출력 차원을 Dim_Head가 아닌 Dim_Model로 구현한 뒤, N개로 차원을 분할하는 방법도 있다. 하지만 차원을 쪼개는 동작을 구현하는 것도 사실 쉽지 않다. 그래서 필자는 전자의 방식을 추천한다.
한편, forward 메서드에 if enc_output is not None: 부분은 추후에 디코더에서 Multi-Head Attention을 구현하기 위해 추가한 코드다. 디코더는 인코더와 다르게 하나의 디코더 블럭에서 Self-Attention동작을 두번하는데, 두번째 동작은 서로 다른 출처의 값을 이용해 linear projection을 수행한다. 따라서 그 경우를 처리해주기 위해 구현하게 되었다.
아래는 MultiHeadAttention 을 구현한 파이토치 코드다.
# Pytorch Implemenation of Single Attention Head
class MultiHeadAttention(nn.Module):
"""
In this class, we implement workflow of Multi-Head Self-Attention
Args:
dim_model: dimension of model's latent vector space, default 512 from official paper
num_heads: number of heads in MHSA, default 8 from official paper for Transformer
dim_head: dimension of each attention head, default 64 from official paper (512 / 8)
dropout: dropout rate, default 0.1
Math:
MSA(z) = [SA1(z); SA2(z); · · · ; SAk(z)]•Umsa
Reference:
https://arxiv.org/abs/1706.03762
"""
def __init__(self, dim_model: int = 512, num_heads: int = 8, dim_head: int = 64, dropout: float = 0.1) -> None:
super(MultiHeadAttention, self).__init__()
self.dim_model = dim_model
self.num_heads = num_heads
self.dim_head = dim_head
self.dropout = dropout
self.attention_heads = nn.ModuleList(
[AttentionHead(self.dim_model, self.dim_head, self.dropout) for _ in range(self.num_heads)]
)
self.fc_concat = nn.Linear(self.dim_model, self.dim_model)
def forward(self, x: Tensor, mask: Tensor, enc_output: Tensor = None) -> Tensor:
""" x is already passed nn.Layernorm """
assert x.ndim == 3, f'Expected (batch, seq, hidden) got {x.shape}'
attention_output = self.fc_concat(
torch.cat([head(x, mask, enc_output) for head in self.attention_heads], dim=-1)
)
return attention_output
MultiHeadAttention 객체는 개별 해드들이 도출한 어텐션 결과를 concat하고 그것을 connect & mix하려고 linear projection을 수행한다.
🔬 Feed Forward Network
# Pytorch Implementation of FeedForward Network
class FeedForward(nn.Module):
"""
Class for Feed-Forward Network module in transformer
In official paper, they use ReLU activation function, but GELU is better for now
We change ReLU to GELU & add dropout layer
Args:
dim_model: dimension of model's latent vector space, default 512
dim_ffn: dimension of FFN's hidden layer, default 2048 from official paper
dropout: dropout rate, default 0.1
Math:
FeedForward(x) = FeedForward(LN(x))+x
"""
def __init__(self, dim_model: int = 512, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(FeedForward, self).__init__()
self.ffn = nn.Sequential(
nn.Linear(dim_model, dim_ffn),
nn.GELU(),
nn.Dropout(p=dropout),
nn.Linear(dim_ffn, dim_model),
nn.Dropout(p=dropout),
)
def forward(self, x: Tensor) -> Tensor:
return self.ffn(x)
피드 포워드는 모델에 non-linearity를 추가하기 위해 사용하는 레이어다. 원본 모델은 ReLU 를 사용하지만 최근 Transformer류 모델에는 GeLU를 사용하는 것이 좀 더 안정적인 학습을 하는데 도움이 된다고 밝혀져, 필자 역시 GeLU를 사용해 구현했다. 또한 논문에는 dropout에 대한 언급이 전혀 없는데, 은닉층의 차원을 저렇게 크게 키웠다 줄이는데 overfitting 이슈가 있을 것 같아서 ViT 논문을 참고해 따로 추가해줬다.
➕ Add & Norm
Residual Connection과 Layernorm을 의미한다. 따로 객체를 만들어서 사용하지는 않고, EncoderLayer 객체에 라인으로 추가해 구현하기 때문에 여기서는 역할과 의미만 설명하고 넘어가겠다.
먼저 Skip-Connection으로도 불리는 Residual Connection은 어떤 레이어를 통과하기 전, 입력 $x$ 를 레이어를 통과하고 나온 결과값 $fx$ 에 더해준다. 따라서 다음 레이어에 통과되는 입력값은 $x+fx$ 가 된다. 왜 이렇게 더해줄까?? 바로 모델의 안정적인 학습을 위해서다. 일단 그전에 명심하고 가야할 전제가 하나 있다. 모델의 레이어가 깊어질수록 레이어마다 값을 조금씩 바꿔나가는 것이 Robust하고 Stable한 결과를 도출할 수 있다는 것이다. 직관적으로 레이어마다 결과가 널뛰기하는 모델보다 안정적으로 차근차근 학습해나가는 모델의 일반화 성능이 더 좋을 것이라고 추측해볼 수 있다. 그래서 Residual Connection 은 입력 $x$ 와 레이어의 이상적인 출력값 $H(x)$ 의 차이가 크지 않음을 가정한다. 만약, 입력 $X$ 를 10.0 , $H(x)$ 를 10.4 라고 해보자. 그럼 Residual Connection 을 사용하는 모델은 0.4에 대해서만 학습을 하면 된다. 한편 이것을 사용하지 않는 모델은 0에서부터 시작해 무려 10.4를 학습해야 한다. 어떤 모델이 학습하기 쉬울까?? 당연히 전자일 것이다. 이렇게 모델이 이상적인 값과 입력의 차이만 학습하면 되기 때문에 이것을 잔차 학습이라고 부르는 것이다.
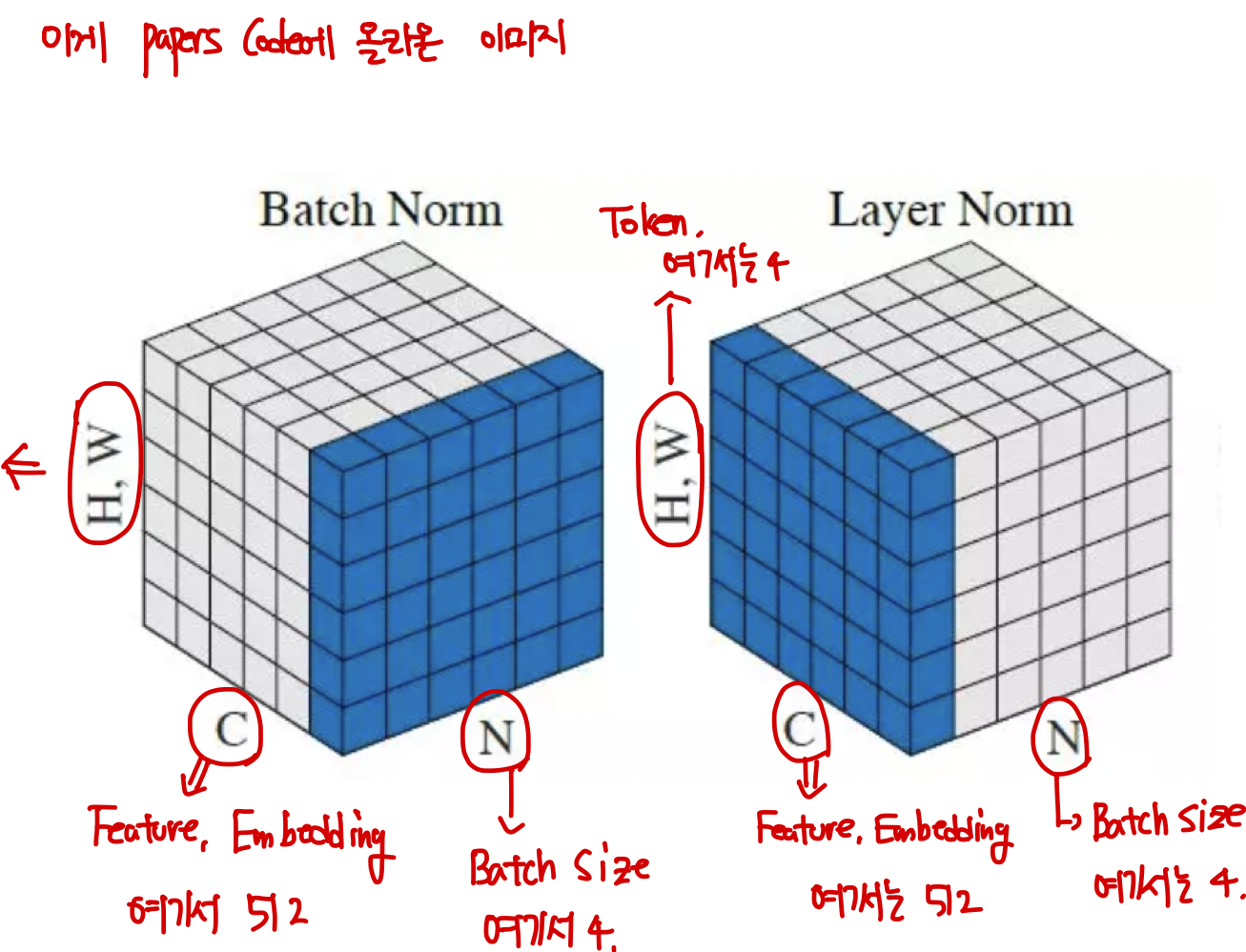
{kind=link}
Batchnorm은 “Mini-Batch” 단위를 Channel(Feature)별로 평균과 표준편차를 구한다면, Layernorm은 Channel(Feature) 단위를 개별 인스턴스별로 평균과 표준편차를 구하여 정규화하는 방식이다.
예를 들어 배치로 4개의 문장을 은닉층의 사이즈가 512인 모델에 입력해줬다고 생각해보자. 그럼 4개의 문장은 각각 512개의 원소를 갖게 되는데, 이것에 대한 평균과 표준편차를 구한다는 것이다. 한 개의 문장당 평균과 표준편차를 1개씩 구해서, 4개의 문장이니까 총 8개가 나오겠다.
그렇다면 왜 Transformer는 Layernorm을 사용했을까?? 자연어 처리는 배치마다 시퀀스의 길이가 고정되어 있지 않아 패딩이나 절삭을 수행한다. 절삭보다는 패딩이 문제가 된다. 패딩은 일반적으로 문장의 끝부분에 해준다. 여기서 Batchnorm을 사용하면 끝쪽에 위치한 다른 시퀀스에 속한 정상적인 토큰들은 패딩에 의해 값이 왜곡될 가능성이 있다. 그래서 Batchnorm 대신 Layernorm을 사용한다. 또한 Batchnorm 은 배치 크기에 종속적이라서 테스트 상황에서는 그대로 사용할 수 없다. 따라서 배치 사이즈에 독립적인 Layernorm을 사용하기도 한다.
한편 이러한 정규화를 왜 사용하는지 궁금하시다면 다른 포스트에 정리를 해뒀으니 참고하시길 바란다. 간단하게만 언급하면, 모델의 비선형성과 그라디언트 크기 사이의 최적의 Trade-Off를 인간이 아닌 모델보고 찾게 만드는게 목적이라 볼 수 있다.
📘 EncoderLayer
이제 Single Encoder Block을 정의하기에 필요한 모든 재료를 살펴봤다. 지금까지의 내용을 종합해 한 개의 인코더 블럭을 만들어보자.
# Pytorch Implementation of Single Encoder Block
class EncoderLayer(nn.Module):
"""
Class for encoder model module in Transformer
In this class, we stack each encoder_model module (Multi-Head Attention, Residual-Connection, LayerNorm, FFN)
We apply pre-layernorm, which is different from original paper
In common sense, pre-layernorm are more effective & stable than post-layernorm
"""
def __init__(self, dim_model: int = 512, num_heads: int = 8, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(EncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(
dim_model,
num_heads,
int(dim_model / num_heads),
dropout,
)
self.layer_norm1 = nn.LayerNorm(dim_model)
self.layer_norm2 = nn.LayerNorm(dim_model)
self.dropout = nn.Dropout(p=dropout)
self.ffn = FeedForward(
dim_model,
dim_ffn,
dropout,
)
def forward(self, x: Tensor, mask: Tensor) -> Tensor:
ln_x = self.layer_norm1(x)
residual_x = self.dropout(self.self_attention(ln_x, mask)) + x
ln_x = self.layer_norm2(residual_x)
fx = self.ffn(ln_x) + residual_x
return fx
지금까지의 내용을 객체 하나에 모아둔거라 특별히 설명이 필요한 부분은 없지만, 필자가 add & norm을 언제 사용했는지 주목해보자. 원본 논문은 Multi-Head Attention과 FeedForward Layer를 통과한 이후에 add & norm을 하는 post-layernorm 방식을 적용했다. 하지만 필자는 두 레이어 통과 이전에 미리 add & norm 을 해주는 pre-layernorm 방식을 채택했다.
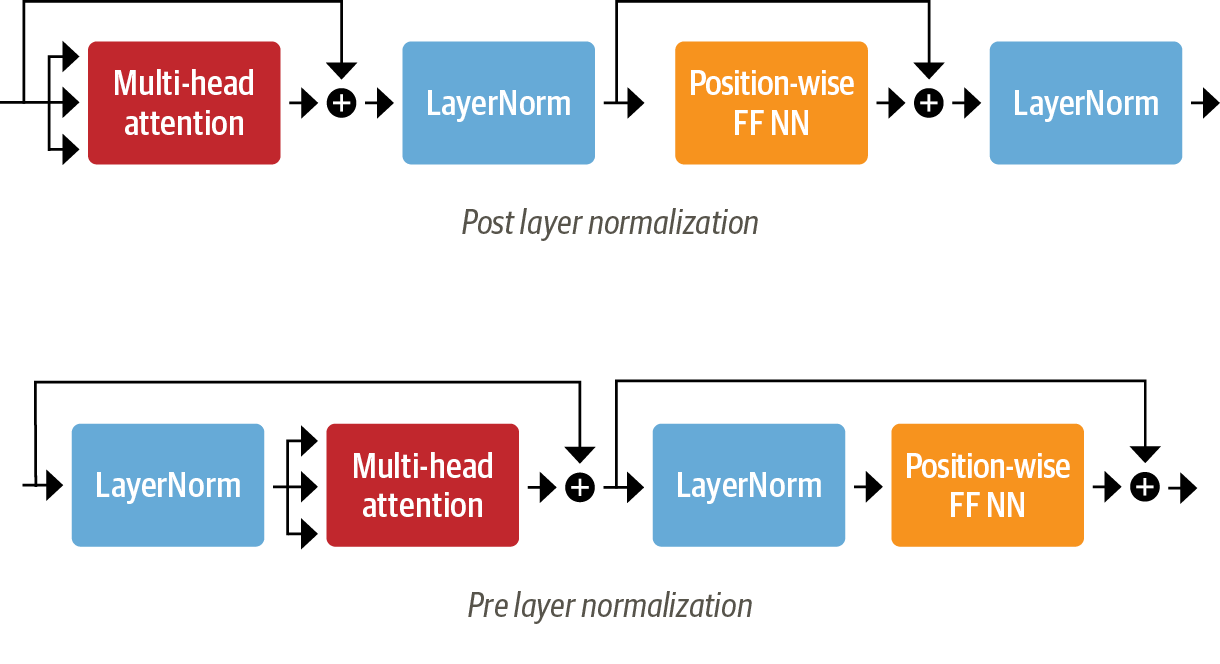 pre-layernorm vs post-layernorm
pre-layernorm vs post-layernorm
{kind=link}
최근 Transformer류의 모델에 pre-layernorm을 적용하는 것이 좀 더 안정적이고 효율적인 학습을 유도할 수 있다고 실험을 통해 밝혀지고 있다. pre-layernorm 을 사용하면 별다른 Gradient Explode 현상이 현저히 줄어들어 복잡한 스케줄러(warmup 기능이 있는 스케줄러)를 사용할 필요가 없어진다고 하니 참고하자.
이렇게 구현한 Single Encoder Block을 이제 N개 쌓기만 하면 드디어 인코더를 완성할 수 있게 된다.
📚 Encoder
드디어 대망의 Encoder 객체 구현을 살펴볼 시간이다.
# Pytorch Implementation of Encoder(Stacked N EncoderLayer)
class Encoder(nn.Module):
"""
In this class, encode input sequence and then we stack N EncoderLayer
First, we define "positional embedding" and then add to input embedding for making "word embedding"
Second, forward "word embedding" to N EncoderLayer and then get output embedding
In official paper, they use positional encoding, which is base on sinusoidal function(fixed, not learnable)
But we use "positional embedding" which is learnable from training
Args:
max_seq: maximum sequence length, default 512 from official paper
N: number of EncoderLayer, default 6 for base model
"""
def __init__(self, max_seq: 512, N: int = 6, dim_model: int = 512, num_heads: int = 8, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(Encoder, self).__init__()
self.max_seq = max_seq
self.scale = torch.sqrt(torch.Tensor(dim_model)) # scale factor for input embedding from official paper
self.positional_embedding = nn.Embedding(max_seq, dim_model) # add 1 for cls token
self.num_layers = N
self.dim_model = dim_model
self.num_heads = num_heads
self.dim_ffn = dim_ffn
self.dropout = nn.Dropout(p=dropout)
self.encoder_layers = nn.ModuleList(
[EncoderLayer(dim_model, num_heads, dim_ffn, dropout) for _ in range(self.num_layers)]
)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, inputs: Tensor, mask: Tensor) -> tuple[Tensor, Tensor]:
"""
inputs: embedding from input sequence, shape => [BS, SEQ_LEN, DIM_MODEL]
mask: mask for Encoder padded token for speeding up to calculate attention score
"""
layer_output = []
pos_x = torch.arange(self.max_seq).repeat(inputs.shape[0]).to(inputs)
x = self.dropout(
self.scale * inputs + self.positional_embedding(pos_x)
)
for layer in self.encoder_layers:
x = layer(x, mask)
layer_output.append(x)
encoded_x = self.layer_norm(x) # from official paper & code by Google Research
layer_output = torch.stack(layer_output, dim=0).to(x.device) # For Weighted Layer Pool: [N, BS, SEQ_LEN, DIM]
return encoded_x, layer_output
역시 지금까지 내용을 종합한 것뿐이라서 크게 특이한 내용은 없고, 구현상 놓치기 쉬운 부분만 알고 넘어가면 된다. forward 메서드의 변수 x를 초기화하는 코드 라인을 주목해보자. 이것이 바로 Input Embedding과 Position Embedding을 더하는(행렬 합) 연산을 구현한 것이다. 이 때 놓치기 쉬운 부분이 바로 Input Embedding에 scale factor를 곱해준다는 것이다. 저자의 주장에 따르면 Input Embedding에만 scale factor를 사용하는 것이 안정적인 학습에 도움이 된다고 하니 참고하자.
한편, 마지막 인코더 블럭에서 나온 임베딩을 다시 한 번 layernorm에 통과하도록 구현했다. 이 부분도 원본 논문에 있는 내용은 아니고 ViT의 논문 내용을 참고해 추가했다.
📘 DecoderLayer
이번에는 디코더에 사용된 블럭의 동작 방식과 의미 그리고 구현까지 알아보자. 사실 디코더도 지금까지 공부한 내용과 크게 다른게 없다. 다만 인코더와는 목적이 다르기 때문에 발생하는 미세한 동작의 차이에 주목해보자. 먼저 Single Decoder Block은 Single Encoder Block과 다르게 Self-Attention을 두 번 수행한다. 지겹겠지만 다시 한 번 Transformer의 목적을 상기시켜보자. 바로 대상 언어를 타겟 언어로 잘 번역하는 것이었다. 일단 인코더를 통해 대상 언어는 잘 이해하게 되었다. 그럼 이제 타겟 언어도 잘 이해해야하지 않은가?? 그래서 타겟 언어를 이해하기 위해 Self-Attention을 한 번, 그리고 대상 언어를 타겟 언어로 번역하기 위해 Self-Attention을 한 번, 총 2번 수행하는 것이다. 첫번째 Self-Attention 을 Masked Multi-Head Attention, 두번째를 Encoder-Decoder Multi-Head Attention이라고 부른다.
🎭 Masked Multi-Head Attention
인코더의 Multi-Head Attention와 행렬 $Q,K,V$ 의 출처가 다르다. 디코더는 출처가 타겟 언어인 linear projection matrix를 사용한다. 또한 인코더와 다르게 개별 시점에 맞는 마스킹 행렬이 필요하다. 디코더의 과업은 결국 대상 언어를 잘 이해하고 그것에 가장 잘 들어맞는 타겟 언어 시퀀스를 generate하는 것이다. 즉, Next Token Prediction을 통해 시퀀스를 만들어내야 한다. 그런데 현재 시점에서 미래 시점에 디코더가 예측해야할 토큰을 미리 알고 있으면 그것을 예측이라고 할 수 있을까?? 디코더가 현재 시점의 토큰을 예측하는데 미래 시점의 Context를 반영하지 못하도록 막기 위해 미리 마스킹 행렬을 정의해 Word_Embedding에 적용해준다. 이렇게 마스킹이 적용된 임베딩 행렬을 가지고 linear projection & self-attention을 수행하기 때문에 이름 앞에 masked를 붙이게 되었다.
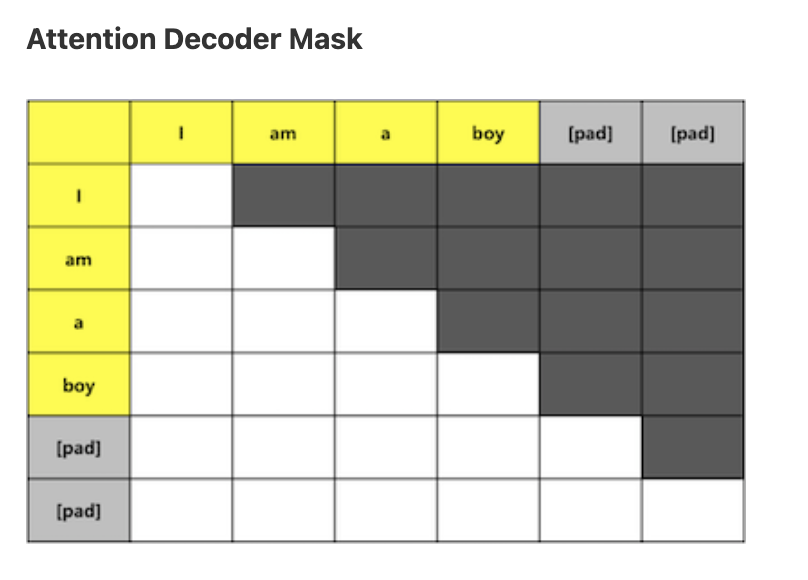 Decoder Language Modeling Mask
Decoder Language Modeling Mask
위 그림은 마스킹을 적용한 Word_Embedding의 모습이다. 첫 번째 시점에서 모델은 자기 자신을 제외한 나머지 Context를 예측에 활용할 수 없다. 그래서 이하 나머지 토큰을 전부 마스킹 처리해줬다. 두번째 시점에서는 직전 시점인 첫번째 토큰과 자기 자신만 참고할 수 있다. 한편, 이렇게 직전 Context만 가지고 현재 토큰을 추론하는 것을 Language Modeling이라 부른다. 그리고 마찬가지로 디코더 역시 시퀀스에 패딩 처리를 해주기 때문에 인코더와 동일한 원리로 만든 decoder padding mask 역시 필요하다.
마스킹 행렬 구현은 최상위 객체인 Transformer의 내부 메서드로 만들었으니, 그 때 자세히 설명하겠다. 이하 나머지 디테일은 인코더의 것과 동일하다.
🪢 Encoder-Decoder Multi-Head Attention
인코더를 통해 이해한 대상 언어 시퀀스와 바로 직전 Self-Attention을 통해 이해한 타겟 언어 시퀀스를 서로 대조하는 레이어다. 우리의 지금 목적은 타겟 언어와 가장 유사한 대상 언어를 찾아 문장을 완성하는 것이다. 따라서 어텐션 계산에 사용될 행렬 $Q$ 의 출처는 직전 레이어인 Masked Multi-Head Attention 의 반환값을 사용하고, 행렬 $K,V$ 는 인코더의 최종 반환값을 사용한다.
한편, 여기 레이어에는 마스킹 행렬이 세 종류나 필요하다. 그 이유는 서로 출처가 다른 두가지 행렬을 계산에 사용하기 때문이다. 지금은 여전히 디코더의 역할을 수행하는 것이기 때문에 직전 레이어에서 사용한 2개의 마스킹 행렬이 그대로 필요하다. 그리고 인코더에서 넘어온 값을 사용한다는 것은 인코더의 패딩 역시 처리가 필요하다는 의미다. 따라서 lm_mask, dec_pad_mask, enc_pad_mask가 필요하다. 역시 마스킹 구현은 최상위 객체 설명 때 함께 살펴보겠다.
👩💻 Implementation
이제 Single Decoder Block의 구현을 살펴보자. 역시 파이토치로 구현했다.
# Pytorch Implementation of Single Decoder Block
class DecoderLayer(nn.Module):
"""
Class for decoder model module in Transformer
In this class, we stack each decoder_model module (Masked Multi-Head Attention, Residual-Connection, LayerNorm, FFN)
We apply pre-layernorm, which is different from original paper
References:
https://arxiv.org/abs/1706.03762
"""
def __init__(self, dim_model: int = 512, num_heads: int = 8, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(DecoderLayer, self).__init__()
self.masked_attention = MultiHeadAttention(
dim_model,
num_heads,
int(dim_model / num_heads),
dropout,
)
self.enc_dec_attention = MultiHeadAttention(
dim_model,
num_heads,
int(dim_model / num_heads),
dropout,
)
self.layer_norm1 = nn.LayerNorm(dim_model)
self.layer_norm2 = nn.LayerNorm(dim_model)
self.layer_norm3 = nn.LayerNorm(dim_model)
self.dropout = nn.Dropout(p=dropout) # dropout is not learnable layer
self.ffn = FeedForward(
dim_model,
dim_ffn,
dropout,
)
def forward(self, x: Tensor, dec_mask: Tensor, enc_dec_mask: Tensor, enc_output: Tensor) -> Tensor:
ln_x = self.layer_norm1(x)
residual_x = self.dropout(self.masked_attention(ln_x, dec_mask)) + x
ln_x = self.layer_norm2(residual_x)
residual_x = self.dropout(self.enc_dec_attention(ln_x, enc_dec_mask, enc_output)) + x # for enc_dec self-attention
ln_x = self.layer_norm3(residual_x)
fx = self.ffn(ln_x) + residual_x
return fx
Self-Attention 레이어가 인코더보다 하나 더 추가되어 add & norm 을 총 3번 해줘야 한다는 것을 제외하고는 크게 구현상의 특이점은 없다. 그저 지금까지 살펴본 블럭을 요리조리 다시 쌓으면 된다.
📚 Decoder
Single Decoder Block을 N개 쌓고 전체 디코더 동작을 수행하는 Decoder 객체의 구현을 알아보자.
# Pytorch Implementation of Decoder(N Stacked Single Decoder Block)
class Decoder(nn.Module):
"""
In this class, decode encoded embedding from encoder by outputs (target language, Decoder's Input Sequence)
First, we define "positional embedding" for Decoder's Input Sequence,
and then add them to Decoder's Input Sequence for making "decoder word embedding"
Second, forward "decoder word embedding" to N DecoderLayer and then pass to linear & softmax for OutPut Probability
Args:
vocab_size: size of vocabulary for output probability
max_seq: maximum sequence length, default 512 from official paper
N: number of EncoderLayer, default 6 for base model
References:
https://arxiv.org/abs/1706.03762
"""
def __init__(
self,
vocab_size: int,
max_seq: int = 512,
N: int = 6,
dim_model: int = 512,
num_heads: int = 8,
dim_ffn: int = 2048,
dropout: float = 0.1
) -> None:
super(Decoder, self).__init__()
self.max_seq = max_seq
self.scale = torch.sqrt(torch.Tensor(dim_model)) # scale factor for input embedding from official paper
self.positional_embedding = nn.Embedding(max_seq, dim_model) # add 1 for cls token
self.num_layers = N
self.dim_model = dim_model
self.num_heads = num_heads
self.dim_ffn = dim_ffn
self.dropout = nn.Dropout(p=dropout)
self.decoder_layers = nn.ModuleList(
[DecoderLayer(dim_model, num_heads, dim_ffn, dropout) for _ in range(self.num_layers)]
)
self.layer_norm = nn.LayerNorm(dim_model)
self.fc_out = nn.Linear(dim_model, vocab_size) # In Pytorch, nn.CrossEntropyLoss already has softmax function
def forward(self, inputs: Tensor, dec_mask: Tensor, enc_dec_mask: Tensor, enc_output: Tensor) -> tuple[Tensor, Tensor]:
"""
inputs: embedding from input sequence, shape => [BS, SEQ_LEN, DIM_MODEL]
dec_mask: mask for Decoder padded token for Language Modeling
enc_dec_mask: mask for Encoder-Decoder Self-Attention, from encoder padded token
"""
layer_output = []
pos_x = torch.arange(self.max_seq).repeat(inputs.shape[0]).to(inputs)
x = self.dropout(
self.scale * inputs + self.positional_embedding(pos_x)
)
for layer in self.decoder_layers:
x = layer(x, dec_mask, enc_dec_mask, enc_output)
layer_output.append(x)
decoded_x = self.fc_out(self.layer_norm(x)) # Because of pre-layernorm
layer_output = torch.stack(layer_output, dim=0).to(x.device) # For Weighted Layer Pool: [N, BS, SEQ_LEN, DIM]
return decoded_x, layer_output
Encoder 객체와 모든 부분이 동일하다. 디테일한 설정만 디코더에 맞게 변경되었을 뿐이다. self.fc_out 에 주목해보자. 디코더는 현재 시점에 가장 적합한 토큰을 예측해야 하기 때문에 디코더의 출력부분에 로짓 계산을 위한 레이어가 필요하다. 그 역할을 하는 것이 바로 self.fc_out이다. 한편, self.fc_out의 출력 차원이 vocab_size으로 되어있는데, 디코더는 디코더가 가진 전체 vocab 을 현재 시점에 적합한 토큰 후보군으로 사용하기 때문이다.
🦾 Transformer
이제 대망의 마지막… 모델의 가장 최상위 객체인 Transformer에 대해서 살펴보자. 객체의 동작은 정리하면 다음과 같다.
- 1) Make
Input Embeddingfor Encoder & Decoder respectively, InitEncoder & DecoderClass - 2) Make 3 types of Masking:
Encoder Padding Mask,Decoder LM & Padding Mask,Encoder-Decoder Mask - 3) Return
Outputfrom Encoder & Decoder
특히 계속 미뤄왔던 마스킹 구현에 대해서 살펴보자. 나머지는 이미 앞에서 많이 설명했으니까 넘어가도록 하겠다. 일단 먼저 코드를 읽어보자. 추가로 Input Embedding 구현은 사용자의 vocab 구축 방식에 따라 달라진다. 필자의 경우 대상 언어와 타겟 언어의 vocab을 분리해 사용하는 것을 가정하고 코드를 만들어 임베딩 레이어를 따로 따로 구현해줬다. vocab을 통합으로 구축하시는 분이라면 하나만 정의해도 상관없다. 대신 나중에 디코더의 로짓값 계산을 위해 개별 언어의 토큰 사이즈는 알고 있어야 할 것이다.
# Pytorch Implementation of Transformer
class Transformer(nn.Module):
"""
Main class for Pure Transformer, Pytorch implementation
There are two Masking Method for padding token
1) Row & Column masking
2) Column masking only at forward time, Row masking at calculating loss time
second method is more efficient than first method, first method is complex & difficult to implement
Args:
enc_vocab_size: size of vocabulary for Encoder Input Sequence
dec_vocab_size: size of vocabulary for Decoder Input Sequence
max_seq: maximum sequence length, default 512 from official paper
enc_N: number of EncoderLayer, default 6 for base model
dec_N: number of DecoderLayer, default 6 for base model
Reference:
https://arxiv.org/abs/1706.03762
"""
def __init__(
self,
enc_vocab_size: int,
dec_vocab_size: int,
max_seq: int = 512,
enc_N: int = 6,
dec_N: int = 6,
dim_model: int = 512,
num_heads: int = 8,
dim_ffn: int = 2048,
dropout: float = 0.1
) -> None:
super(Transformer, self).__init__()
self.enc_input_embedding = nn.Embedding(enc_vocab_size, dim_model)
self.dec_input_embedding = nn.Embedding(dec_vocab_size, dim_model)
self.encoder = Encoder(max_seq, enc_N, dim_model, num_heads, dim_ffn, dropout)
self.decoder = Decoder(dec_vocab_size, max_seq, dec_N, dim_model, num_heads, dim_ffn, dropout)
@staticmethod
def enc_masking(x: Tensor, enc_pad_index: int) -> Tensor:
""" make masking matrix for Encoder Padding Token """
enc_mask = (x != enc_pad_index).int().repeat(1, x.shape[-1]).view(x.shape[0], x.shape[-1], x.shape[-1])
return enc_mask
@staticmethod
def dec_masking(x: Tensor, dec_pad_index: int) -> Tensor:
""" make masking matrix for Decoder Masked Multi-Head Self-Attention """
pad_mask = (x != dec_pad_index).int().repeat(1, x.shape[-1]).view(x.shape[0], x.shape[-1], x.shape[-1])
lm_mask = torch.tril(torch.ones(x.shape[0], x.shape[-1], x.shape[-1]))
dec_mask = pad_mask * lm_mask
return dec_mask
@staticmethod
def enc_dec_masking(enc_x: Tensor, dec_x: Tensor, enc_pad_index: int) -> Tensor:
""" make masking matrix for Encoder-Decoder Multi-Head Self-Attention in Decoder """
enc_dec_mask = (enc_x != enc_pad_index).int().repeat(1, dec_x.shape[-1]).view(
enc_x.shape[0], dec_x.shape[-1], enc_x.shape[-1]
)
return enc_dec_mask
def forward(self, enc_inputs: Tensor, dec_inputs: Tensor, enc_pad_index: int, dec_pad_index: int) -> tuple[Tensor, Tensor, Tensor, Tensor]:
enc_mask = self.enc_masking(enc_inputs, enc_pad_index) # enc_x.shape[1] == encoder input sequence length
dec_mask = self.dec_masking(dec_inputs, dec_pad_index) # dec_x.shape[1] == decoder input sequence length
enc_dec_mask = self.enc_dec_masking(enc_inputs, dec_inputs, enc_pad_index)
enc_x, dec_x = self.enc_input_embedding(enc_inputs), self.dec_input_embedding(dec_inputs)
enc_output, enc_layer_output = self.encoder(enc_x, enc_mask)
dec_output, dec_layer_output = self.decoder(dec_x, dec_mask, enc_dec_mask, enc_output)
return enc_output, dec_output, enc_layer_output, dec_layer_output
마스킹의 필요성이나 동작 방식은 이미 위에서 모두 설명했기 때문에 구현상 특징만 설명하려한다. 세가지 마스킹 모두 공통적으로 구현 코드 라인에 .int() 가 들어가 있다. 그 이유는 $\frac{Q•K^T}{\sqrt{d_h}}$에 마스킹을 적용할 때 torch.masked_fill 메서드를 사용하기 때문이다. 무슨 이유 때문인지는 모르겠으나 torch.masked_fill의 경우 마스킹 조건으로 boolean을 전달하면 마스킹이 제대로 구현되지 않는 현상이 있었다. 한편, 정수값으로 조건을 구현하면 의도한대로 구현이 되는 것을 확인했다. 그래서 패딩에 해당되는 토큰이 위치한 곳의 원소값을 정수형 Binary 로 만들어주기 위해 int() 를 사용한 것이다.
🎭 Decoder Mask
디코더는 총 2가지의 마스킹이 필요하다고 언급했었다. pad_mask의 경우는 인코더의 것과 동일한 원리를 사용하기 때문에 설명을 생략하겠다. lm_mask 의 경우는 torch.tril을 이용해 하삼각행렬 형태로 마스킹 행렬 정의가 쉽게 가능하다.
한편, 2개의 마스킹을 동시에 디코더 객체에 넘기는 것은 매우 비효율적이다. 따라서 pad_mask 와 lm_mask의 합집합에 해당하는 행렬을 만들어 최종 디코더의 마스킹으로 전달한다.
🙌 Encoder-Decoder Mask
이번 경우는 마스킹의 행방향 차원은 디코더 입력값의 시퀀스 길이, 열방향 차원은 인코더 입력값의 시퀀스 길이로 설정해야 한다. 그 이유는 다른 Self-Attention 레이어와 다르게 서로 다른 출처를 통해 만든 행렬을 사용하기 때문에 $\frac{Q•K^T}{\sqrt{d_h}}$의 모양이 정사각행렬이 아닐 수도 있다. 예를 들어 한국어 문장을 영어로 바꾸는 경우를 생각해보자. 같은 뜻이 담긴 문장이라고 해서 두 문장의 길이가 같은가?? 아니다. 서로 다른 언어라면 거의 대부분의 경우 길이가 다를 것이다. 따라서 $\frac{Q•K^T}{\sqrt{d_h}}$의 행방향은 디코더의 시퀀스 길이에 따르고 열방향은 인코더의 시퀀스 길이에 따르도록 마스킹 역시 구현해줘야 한다.
그리고 이번 마스킹을 만드는 목적이 인코더의 패딩을 마스킹 처리해주기 위함이기 때문에 enc_pad_index 매개변수에는 인코더 vocab에서 정의한 pad_token_ID를 전달하면 된다.
# scaled_dot_product_attention의 일부
if mask is not None:
attention_matrix = attention_matrix.masked_fill(mask == 0, float('-inf'))
이렇게 구현된 마스킹은 scaled_dot_product_attention 메서드에 구현된 조건문을 통해 마스킹 대상을 -∞으로 변환하는 역할을 하게 된다.
Leave a comment