
🪢 [DeBERTa] DeBERTa: Decoding-Enhanced BERT with Disentangled-Attention
![]() Updated:
Updated:
🔭 Overview
DeBERTa는 2020년 Microsoft가 ICLR에서 발표한 자연어 처리용 신경망 모델이다. Disentangled Self-Attention, Enhanced Mask Decoder라는 두가지 새로운 테크닉을 BERT, RoBERTa에 적용해 당시 SOTA를 달성했으며, 특히 영어처럼 문장에서 자리하는 위치에 따라 단어의 의미, 형태가 결정되는 굴절어 계열에 대한 성능이 좋아 꾸준히 사랑받고 있는 모델이다. 또한 인코딩 가능한 최대 시퀀스 길이가 4096으로 매우 긴 편 (DeBERTa-V3-Large) 에 속해, Kaggle Competition에서 자주 활용된다. 출시된지 2년이 넘도록 SuperGLUE 대시보드에서 꾸준히 상위권을 유지하고 있다는 점도 DeBERTa가 얼마나 잘 설계된 모델인지 알 수 있는 대목이다.
한편, DeBERTa의 설계 철학은 Inductive Bias 다. 간단하게 Inductive Bias란, 주어진 데이터로부터 일반화 성능을 높이기 위해 "입력되는 데이터는 ~ 할 것이다", "이런 특징을 갖고 있을 것이다"와 같은 가정, 가중치, 가설 등을 기계학습 알고리즘에 적용하는 것을 말한다. ViT 논문 리뷰에서도 밝혔듯, 퓨어한 Self-Attention 의 Inductive Bias 는 사실상 없으며, 전체 Transformer 구조 레벨에서 봐도 Absolute Position Embedding을 사용해 토큰의 위치 정보를 모델에 주입해주는 것이 그나마 약한 Iniductive Bias라고 볼 수 있다. 다른 포스팅에서는 분명 Inductive Bias 가 적기 때문에 자연어 처리에서 Transformer 가 성공을 거둘 수 있다고 해놓고 이게 지금 와서 말을 뒤집는다고 생각할 수 있다. 하지만 Self-Attention과 Absolute Position Embedding의 의미를 다시 한 번 상기해보면, Inductive Bias 추가를 주장하는 저자들의 생각이 꽤나 합리적이었음을 알 수 있게 된다. 구체적인 모델 구조를 파악하기 전에 먼저 Inductive Bias 추가가 왜 필요하며, 어떠한 가정이 필요한지 알아보자.
🪢 Inducitve Bias in DeBERTa
Absolute Position + Relative Position을 모두 활용해 풍부하고 깊은 임베딩 추출단어의 발생 순서임베딩과단어 분포 가설임베딩을 모두 추출하는 것을 목적으로 설계
본 논문 초록에는 다음과 같은 문장이 서술되어 있다.
motivated by the observation that the attention weight of a word pair depends on not only their contents but their relative positions. For example, the dependency between the words “deep” and “learning” is much stronger when they occur next to each other than when they occur in different sentences.
위의 두 문장이 DeBERTa의 Inducitve Bias 를 가장 잘 설명하고 있다고 생각한다. 저자가 추가를 주장하는 Inductive Bias란, relative position 정보라는 것과 기존 모델링으로는 relative position이 주는 문맥 정보 포착이 불가능하다는 사실을 알 수 있다.
그렇다면 relative position 가 제공하는 문맥 정보가 도대체 뭐길래 기존의 방식으로는 포착이 불가능하다는 것일까?? 자연어에서 포착 가능한 문맥들의 종류와 기존의 모델링 방식에 대한 정리부터 해보자. 여기서 말하는 기존 방식이란, 퓨어한 Self-Attention과 Absolute Position Embedding 을 사용하는 Transformer-Encoder-Base 모델(BERT, RoBERTa)을 뜻한다. 이번 포스팅에서는 BERT를 기준으로 설명하겠다.
📚 Types of Embedding
먼저 현존하는 모든 임베딩(벡터에 문맥을 주입하는)기법들을 정리해보자. 다음과 같이 3가지 카테고리로 분류가 가능하다.
- 1) 단어의 빈도수: 시퀀스에서 사용된 토큰들의 빈도수를 측정(
Bag of words) - 2) 단어의 발생 순서:
corpus내부의 특정sequence등장 빈도를 카운트(N-Gram), 주어진 시퀀스를 가지고 다음 시점에 등장할 토큰을 맞추는 방식(LM) - 3) 단어 분포 가설 : 단어의 의미는 주변 문맥에 의해 결정된다는 가정, 어떤 단어 쌍이 자주 같이 등장하는지 카운트해
PMI를 측정하는 방식(Word2Vec)
기존의 모델링 방식은 어디에 포함될까?? BERT 는 대분류 상 신경망에 포함되고, Language Modeling을 통해 시퀀스를 학습한다는 점 그리고 Self-Attention과 Absolute Position Embedding 을 사용한다는 점에서 2번, 단어의 발생 순서 에 포함된다고 볼 수 있다. Absolute Position Embedding 과 Self-Attention의 사용이 퓨어한 BERT가 분류상 2번이라는 사실을 뒷받침하는 증거라는 점에서 의아할 수 있다. 하지만 잘 생각해보자.
Absolute Position Embedding은 주어진 시퀀스의 길이를 측정한 뒤, 나열된 순서 그대로 forward하게 0부터 길이-1의 번호를 개별 토큰에 할당한다. 다시 말해, 단어가 시퀀스에서 발생한 순서를 수학적으로 표현해 모델에 주입한다는 의미가 된다. Self-Attention은 Absolute Position Embedding 정보가 주입된 시퀀스 전체를 한 번에 병렬 처리한다. 따라서 충분히 BERT 같은 Self-Attention, Absolute Position Embedding 기반 모델을 2번에 분류할 수 있겠다.
한편, 혹자는 "BERT는 MLM 을 사용하는데 Language Modeling을 한다고 하는게 맞나요"라고 말할 수 있다. 하지만 MLM 역시 대분류 상 Language Modeling 기법에 속한다. 다만, Bi-Directional하게 문맥을 파악하고 LM을 하니까 정말 엄밀히 따지면 3번의 속성도 조금은 있다고 보는게 무리는 아니라 생각한다. MLM 사용으로 더 많은 정보를 포착해 임베딩을 만들기 때문에 초기 BERT가 GPT보다 NLU에서 상대적으로 강점을 가졌던 것 아닐까 싶다.
🔢 Relative Position Embedding
이제 Relative Position Embedding이 무엇이고, 도대체 어떤 문맥 정보를 포착한다는 것인지 알아보자. Relative Position Embedding 이란, 시퀀스 내부 토큰 사이의 위치 관계 표현을 통해 토큰 사이의 relation을 pairwise하게 학습하는 위치 임베딩 기법을 말한다. 일반적으로 상대 위치 관계는 서로 다른 두 토큰의 시퀀스 인덱스 값의 차를 이용해 나타낸다. 포착하는 문맥 정보는 예시와 함깨 설명하겠다. 딥러닝이라는 단어는 영어로 Deep Learning 이다. 두 단어를 합쳐놓고 보면 신경망을 사용하는 머신러닝 기법의 한 종류라는 의미를 갖겠지만, 따로 따로 보면 깊은, 배움이라는 개별적인 의미로 나뉜다.
1) The Deep Learning is the Best Technique in Computer Science2) I’m learning how to swim in the deep ocean
Deep과 Learning의 상대적인 거리에 주목하면서 두 문장을 해석해보자. 첫 번째 문장에서 두 단어는 이웃하게 위치해 신경망을 사용하는 머신러닝 기법의 한 종류 라는 의미를 만들어내고 있다. 한편 두 번째 문장에서 두 단어는 띄어쓰기 기준 5개의 토큰만큼 떨어져 위치해 각각 배움, 깊은 이라는 의미를 만들어 내고 있다. 이처럼 개별 토큰 사이의 위치 관계에 따라서 파생되는 문맥적 정보를 포착하려는 의도로 설계된 기법이 바로 Relative Position Embedding 이다.
pairwise 하게 relation 을 포착한다는 점으로 보아 skip-gram의 negative sampling과 매우 유사한 느낌의 정보를 포착할 것이라고 예상되며 카테고리 분류상 3번, 단어 분포 가설에 포함시킬 수 있을 것 같다. (필자의 개인적인 의견이니 이 부분에 대한 다른 의견이 있다면 꼭 댓글에 적어주시면 감사하겠습니당🥰).
위 예시만으로는 상대 위치 임베딩 개념이 와닿지 않을 수 있다. 그렇다면 옆에 링크를 먼저 읽고 오자. (링크1)
Relative Position Embedding 을 실제 어떻게 코드로 구현하는지, 본 논문에서는 위치 관계를 어떻게 정의했는지 Absolute Position Embedding와 비교를 통해 알아보자. 다음과 같은 두 개의 문장이 있을 때, 개별 위치 임베딩 방식이 문장의 위치 정보를 인코딩하는 과정을 파이썬 코드로 작성해봤다. 함께 살펴보자.
A) I love studying deep learning so muchB) I love deep cheeze burguer so much
# Absolute Position Embedding
>>> max_length = 7
>>> position_embedding = nn.Embedding(7, 512) # [max_seq, dim_model]
>>> pos_x = position_embedding(torch.arange(max_length))
>>> pos_x, pos_x.shape
(tensor([[ 0.4027, 0.9331, 1.0556, ..., -1.7370, 0.7799, 1.9851], # A,B의 0번 토큰: I
[-0.2206, 2.1024, -0.6055, ..., -1.1342, 1.3956, 0.9017], # A,B의 1번 토큰: love
[-0.9560, -0.0426, -1.8587, ..., -0.9406, -0.1467, 0.1762], # A,B의 2번 토큰: studying, deep
..., # A,B의 3번 토큰: deep, cheeze
[ 0.5999, 0.5235, -0.3445, ..., 1.9020, -1.5003, 0.7535], # A,B의 4번 토큰: learning, burger
[ 0.0688, 0.5867, -0.0340, ..., 0.8547, -0.9196, 1.1193], # A,B의 5번 토큰: so
[-0.0751, -0.4133, 0.0256, ..., 0.0788, 1.4665, 0.8196]], # A,B의 6번 토큰: much
grad_fn=<EmbeddingBackward0>),
torch.Size([7, 512]))
Absolute Position Embedding은 주위 문맥에 상관없이 같은 위치의 토큰이라면 같은 포지션 값으로 인코딩하기 때문에 512개의 원소로 구성된 행벡터들의 인덱스를 실제 문장에서 토큰의 등장 순서에 맵핑해주는 방식으로 위치 정보를 표현한다. 예를 들면, 문장에서 가장 먼저 등장하는 0번 토큰에 0번째 행벡터를 배정하고 가장 마지막에 등장하는 N-1 번째 토큰은 N-1번째 행벡터를 위치 정보값으로 갖는 방식이다. 전체 시퀀스 관점에서 개별 토큰에 번호를 부여하기 때문에 syntactical한 정보를 모델링 해주기 적합하다는 장점이 있다.
Absolute Position Embedding 은 일반적으로 Input Embedding과 행렬합 연산을 통해 Word Embedding 으로 만들어 인코더의 입력으로 사용한다.
아래 코드는 저자가 논문에서 제시한 DeBERTa의 Relative Position Embedding 구현을 파이토치로 옮긴 것이다. Relative Position Embedding 은 절대 위치에 비해 꽤나 복잡한 과정을 거쳐야 하기 때문에 코드 역시 긴 편이다. 하나 하나 천천히 살펴보자.
# Relative Position Embedding
>>> position_embedding = nn.Embedding(2*max_length, dim_model)
>>> x, p_x = torch.randn(max_length, dim_model), position_embedding(torch.arange(2*max_length))
>>> fc_q, fc_kr = nn.Linear(dim_model, dim_head), nn.Linear(dim_model, dim_head)
>>> q, kr = fc_q(x), fc_kr(p_x) # [batch, max_length, dim_head], [batch, 2*max_length, dim_head]
>>> tmp_c2p = torch.matmul(q, kr.transpose(-1, -2))
>>> tmp_c2p, tmp_c2p.shape
(tensor([[ 2.8118, 0.8449, -0.6240, -0.6516, 3.4009, 1.8296, 0.8304, 1.0164,
3.5664, -1.4208, -2.0821, 1.5752, -0.9469, -7.1767],
[-2.1907, -3.2801, -2.0628, 0.4443, 2.2272, -5.6653, -4.6036, 1.4134,
-1.1742, -0.3361, -0.4586, -1.1827, 1.0878, -2.5657],
[-4.8952, -1.5330, 0.0251, 3.5001, 4.1619, 1.7408, -0.5100, -3.4616,
-1.6101, -1.8741, 1.1404, 4.9860, -2.5350, 1.0999],
[-3.3437, 4.2276, 0.4509, -1.8911, -1.1069, 0.9540, 1.2045, 2.2194,
-2.6509, -1.4076, 5.1599, 1.6591, 3.8764, 2.5126],
[ 0.8164, -1.9171, 0.8217, 1.3953, 1.6260, 3.8104, -1.0303, -2.1631,
3.9008, 0.5856, -1.6212, 1.7220, 2.7997, -1.8802],
[ 3.4473, 0.9721, 3.9137, -3.2055, 0.6963, 1.2761, -0.2266, -3.7274,
-1.4928, -1.9257, -5.4422, -1.8544, 1.8749, -3.4923],
[ 2.6639, -1.4392, -3.8818, -1.4120, 1.7542, -0.8774, -3.0795, -1.2156,
-1.0852, 3.7825, -3.5581, -3.6989, -2.6705, -1.2262]],
grad_fn=<MmBackward0>),
torch.Size([7, 14]))
>>> max_seq, max_pos = 7, max_seq * 2
>>> q_index, k_index = torch.arange(max_seq), torch.arange(max_seq)
>>> q_index, k_index
(tensor([0, 1, 2, 3, 4, 5, 6]), tensor([0, 1, 2, 3, 4, 5, 6]))
>>> tmp_pos = q_index.view(-1, 1) - k_index.view(1, -1)
>>> rel_pos_matrix = tmp_pos + max_relative_position
>>> rel_pos_matrix
tensor([[ 7, 6, 5, 4, 3, 2, 1],
[ 8, 7, 6, 5, 4, 3, 2],
[ 9, 8, 7, 6, 5, 4, 3],
[10, 9, 8, 7, 6, 5, 4],
[11, 10, 9, 8, 7, 6, 5],
[12, 11, 10, 9, 8, 7, 6],
[13, 12, 11, 10, 9, 8, 7]])
>>> rel_pos_matrix = torch.clamp(rel_pos_matrix, 0, max_pos - 1).repeat(10, 1, 1)
>>> tmp_c2p = tmp_c2p.repeat(10, 1, 1)
>>> rel_pos_matrix, rel_pos_matrix.shape, tmp_c2p.shape
(tensor([[[ 7, 6, 5, 4, 3, 2, 1],
[ 8, 7, 6, 5, 4, 3, 2],
[ 9, 8, 7, 6, 5, 4, 3],
[10, 9, 8, 7, 6, 5, 4],
[11, 10, 9, 8, 7, 6, 5],
[12, 11, 10, 9, 8, 7, 6],
[13, 12, 11, 10, 9, 8, 7]],
torch.Size([10, 7, 14]),
torch.Size([10, 7, 14]))
>>> outputs = torch.gather(tmp_c2p, dim=-1, index=rel_pos_matrix)
>>> outputs, outputs.shape
(tensor([[[ 1.0164, 0.8304, 1.8296, 3.4009, -0.6516, -0.6240, 0.8449],
[-1.1742, 1.4134, -4.6036, -5.6653, 2.2272, 0.4443, -2.0628],
[-1.8741, -1.6101, -3.4616, -0.5100, 1.7408, 4.1619, 3.5001],
[ 5.1599, -1.4076, -2.6509, 2.2194, 1.2045, 0.9540, -1.1069],
[ 1.7220, -1.6212, 0.5856, 3.9008, -2.1631, -1.0303, 3.8104],
[ 1.8749, -1.8544, -5.4422, -1.9257, -1.4928, -3.7274, -0.2266],
[-1.2262, -2.6705, -3.6989, -3.5581, 3.7825, -1.0852, -1.2156]],
.....
[[ 1.0164, 0.8304, 1.8296, 3.4009, -0.6516, -0.6240, 0.8449],
[-1.1742, 1.4134, -4.6036, -5.6653, 2.2272, 0.4443, -2.0628],
[-1.8741, -1.6101, -3.4616, -0.5100, 1.7408, 4.1619, 3.5001],
[ 5.1599, -1.4076, -2.6509, 2.2194, 1.2045, 0.9540, -1.1069],
[ 1.7220, -1.6212, 0.5856, 3.9008, -2.1631, -1.0303, 3.8104],
[ 1.8749, -1.8544, -5.4422, -1.9257, -1.4928, -3.7274, -0.2266],
[-1.2262, -2.6705, -3.6989, -3.5581, 3.7825, -1.0852, -1.2156]]],
grad_fn=<GatherBackward0>),
torch.Size([10, 7, 7]))
일단 절대 위치와 동일하게 nn.Embedding을 사용해 임베딩 룩업 테이블(레이어)를 정의하지만, 입력 차원이 다르다. 절대 위치 임베딩은 forward하게 위치값을 맵핑해야 하는 반면에 상대 위치 임베딩 방식은 Bi-Directional한 맵핑을 해야 해서, 기존 max_length 값의 두 배를 입력 차원(max_pos)으로 사용했다. 예를 들어 0번 토큰과 나머지 토큰 사이의 위치 관계를 표현해야 하는 상황이다. 그렇다면 우리는 0번 토큰과 나머지 토큰과의 위치 관계를 [0, -1, -2, -3, -4, -5, -6] 으로 인코딩할 수 있다.
반대로 마지막 6번 토큰과 나머지 토큰 사이의 위치 관계를 표현하는 경우라면 어떻게 될까?? [6, 5, 4, 3, 2, 1, 0] 으로 인코딩 될 것이다. 다시 말해, 위치 임베딩 원소 값은 [-max_seq:max_seq] 사이에서 정의된다는 것이다. 그러나 원소값의 범위를 그대로 사용할 수는 없다. 이유는 파이썬의 리스트, 텐서 같은 배열형 자료구조는 음이 아닌 정수를 인덱스로 활용해야 forward 하게 원소에 접근할 수 있기 때문이다. 일반적으로 배열 형태의 자료형은 모두 인덱스 0부터 N-1까지 순차적으로 맵핑된다. 그래서 의도한대로 토큰에 접근하려면 역시 토큰의 인덱스를 forward 한 형태로 만들어줘야 한다.
따라서 기존 [-max_seq:max_seq] 에 max_seq를 더해준 [0:2*max_seq] (2 * max_seq)을 원소 값의 범위로 사용하게 된다. 여기까지가 통상적으로 말하는 Relative Position Embedding 에 해당한다. 위 코드상으로는 rel_pos_matrix 를 만든 부분에 해당한다.
이제부터 저자가 주장하는 위치 관계 표현 방식에 대해 알아보자. 일반적인 Relative Position Embedding과 거의 유사하지만, rel_pos_matrix 내부 원소 값이 음수가 되거나 max_pos 을 초과하는 경우를 처리 해주기 위해 후처리 과정을 도입해 사용했다. 예외 상황은 max_seq > 1/2 * max_pos(==k) 일 때 발생한다. official repo 의 코드를 보면 max_seq와 k를 일치시켜 모델링 하기 때문에 파인튜닝 하는 상황이라면 이것을 몰라도 상관없겠지만, 하나 하나 모델을 직접 만드는 입장이라면 예외 상황을 반드시 기억하자.
한편, 이러한 인코딩 방식은 word2vec 의 window size 도입과 비슷한 원리(의미는 주변 문맥에 의해 결정)라고 생각하면 되는데, 윈도우 사이즈 범위에서 벗어난 토큰들은 주변 문맥으로 인정 하지 않겠다는(negative sample) 의도를 갖고 있다. 실제 구현은 텐서 내부 원소값의 범위를 사용자 지정 범위로 제한할 수 있는 torch.clamp 를 사용하면 1줄로 깔끔하게 만들 수 있으니 참고하자.
torch.clamp 까지 적용하고 난 최종 결과를 살펴보자. 행백터, 열벡터 모두 [0:2*max_seq] 사이에서 정의되고 있으며, 개별 방향 벡터 원소의 최대값과 최소값의 차이가 항상 k 로 유지 된다. 의도대로 정확히 윈도우 사이즈만큼의 주변 맥락을 반영해 임베딩을 형성하고 있음을 알 수 있다.
정리하면, Relative Position Embedding 란 절대 위치 방식처럼 임베딩 룩업 테이블을 만들되, 사용자가 지정한 윈도우 사이즈에 해당하는 토큰의 임베딩 값만 추출해 새로운 행벡터를 여러 개 만들어 내는 기법이라고 할 수 있다. 이 때 행벡터는 대상 토큰과 그 나머지 토큰 사이의 위치 변화에 따라 발생하는 파생적인 맥락 정보를 담고 있다.
🤔 Word Context vs Relative Position vs Absolute Position

지금까지 Relative Position Embedding이 무엇이고, 도대체 어떤 문맥 정보를 포착한다는 것인지 알아봤다. 필자의 설명이 매끄럽지 못하기도 하고 예시를 텍스트로 들고 있어서 직관적으로 word context는 무엇인지, Position 정보와는 뭐가 다른지, 두 가지 Position 정보는 뭐가 어떻게 다른지 와닿지 않는 분들이 많으실 것 같다. 그래서 최대한 직관적인 예시를 통해 세가지 정보의 차이점을 설명해보려 한다. (필자 본인이 햇갈려서 쓰는 건 비밀이다)
사람 5명이 공항 체크인을 위해 서 있다. 모두 왼쪽을 보고 있는 것을 보아 왼쪽에 키가 제일 작은 여자가 가장 앞줄이라고 볼 수 있겠다. 우리는 줄 서있는 순서대로 5명의 사람에게 번호를 부여할 것이다. 편의상 0번부터 시작해 4번까지 번호를 주겠다. 1번에 해당하는 사람은 누구인가?? 바로 줄의 2번째에 서있는 여자다. 그럼 2번에 해당하는 사람은 누구인가?? 사진 속 줄의 가장 중간에 있는 남자가 2번이다. 이렇게 그룹 단위(전체 줄)에서 개개인에 일련의 번호를 부여해 위치를 표현하는 방법이 바로 Absolute Position Embedding이다.
한편, 다시 2번 사람에게 주목해보자. 우리는 2번 남자를 전체 줄에서 가운데 위치한 사람이 아니라, 검정색 양복과 구두를 신고 손에 쥔 무언가를 응시하고 있는 사람이라고 표현할 수도 있다. 이것이 바로 토큰의 의미 정보를 담은 word context에 해당한다.
마지막으로 Relative Position Embedding 방식으로 2번 남자를 표현해보자. 오른손으로는 커피를 들고 다른 손으로는 캐리어를 잡고 있으며 검정색 하이힐과 베이지색 바지를 입은 1번 여자의 뒤에 있는 사람, 회색 양복과 검은 뿔테 안경을 쓰고 한 손에는 캐리어를 잡고 있는 4번 여자의 앞에 있는 사람, 검정색 자켓과 청바지를 입고 한 손에는 회색 코트를 들고 있는 줄의 맨 앞 여자로부터 2번째 뒤에 서있는 사람, 턱수염이 길고 머리가 긴 편이며 파란색 가디건을 입고 초록색과 검정색이 혼합된 가방을 왼쪽으로 메고 있는 남자로부터 2번째 앞에 있는 사람.
이처럼 표현하는게 바로 Relative Position Embedding에 대응된다고 볼 수 있다. 이제 위 예시를 자연어 처리에 그대로 대입시켜보면 이해가 한결 수월할 것이다.
🤔 DeBERTa Inductive Bias
결국 DeBERTa는 두가지 위치 정보 포착 방식을 적절히 섞어서 모델이 더욱 풍부한 임베딩을 갖도록 하려는 의도로 설계 되었다. 또한 우리는 이미 모델이 다양한 맥락 정보를 포착할수록 NLU Task 에서 더 나은 성능을 기록한다는 사실을 BERT와 GPT 사례에서 알 수 있었다. 따라서 Relative Position Embedding 을 추가하여 단어의 발생 순서 를 포착하는 모델에 단어 분포 가설 적인 특징을 더해주려는 저자의 아이디어는 매우 타당하다고 볼 수 있겠다.
이제 관건은 “두가지 위치 정보를 어떤 방식으로 추출하고 섞어줄 것인가” 하는 물음에 답하는 것이다. 저자는 물음에 답하기 위해 Disentangled Self-Attention 과 Enhanced Mask Decoder 라는 새로운 기법 두가지를 제시한다. 전자는 단어 분포 가설 에 해당되는 맥락 정보를 추출하기 위한 기법이고, 후자는 단어 발생 순서 에 포함되는 임베딩을 모델에 주입하기 위해 설계되었다. 모델링 파트에서는 두가지 새로운 기법에 대해서 자세히 살펴본 뒤, 모델을 코드로 빌드하는 과정을 설명하려 한다.
코드는 논문의 내용과 microsoft의 공식 git repo를 참고해 만들었음을 밝힌다. 다만, 논문에서 모델 구현과 관련해 세부적인 내용은 상당수 생략하고 있으며, repo에 공개된 코드는 hard coding되어 그 의도를 정확하게 파악하는데 많은 어려움이 있었다. 그래서 어느 정도는 필자의 주관적인 생각이 반영된 코드라는 점을 미리 밝힌다.
🌟 Modeling
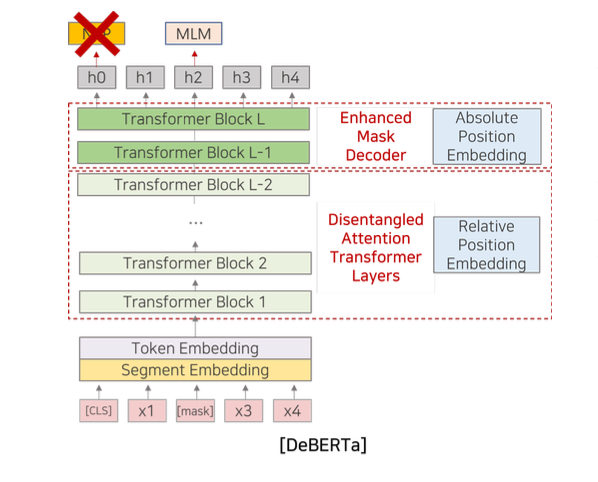
- 1) Disentangled Self-Attention Encoder Block for
Relative Position Embedding - 2) Enhanced Mask Decoder for
Absolute Position Embedding
DeBERTa 의 전반적인 구조는 일반적인 BERT, RoBERTa와 크게 다른 점이 없다. 다만, 모델의 초반부 Input Embedding 에서 Absolute Position 정보를 추가하는 부분이 후반부 Enhanced Mask Decoder라 부르는 인코더 블록으로 옮겨간 것과 Disentangled Self-Attention 을 위해 개별 인코더 블록마다 상대 위치 정보를 출처로 하는 linear projection 레이어가 추가되었음을 명심하자. 또한, DeBERTa의 pre-train 은 RoBERTa처럼 NSP를 삭제하고 MLM만 사용한 점도 기억하자.
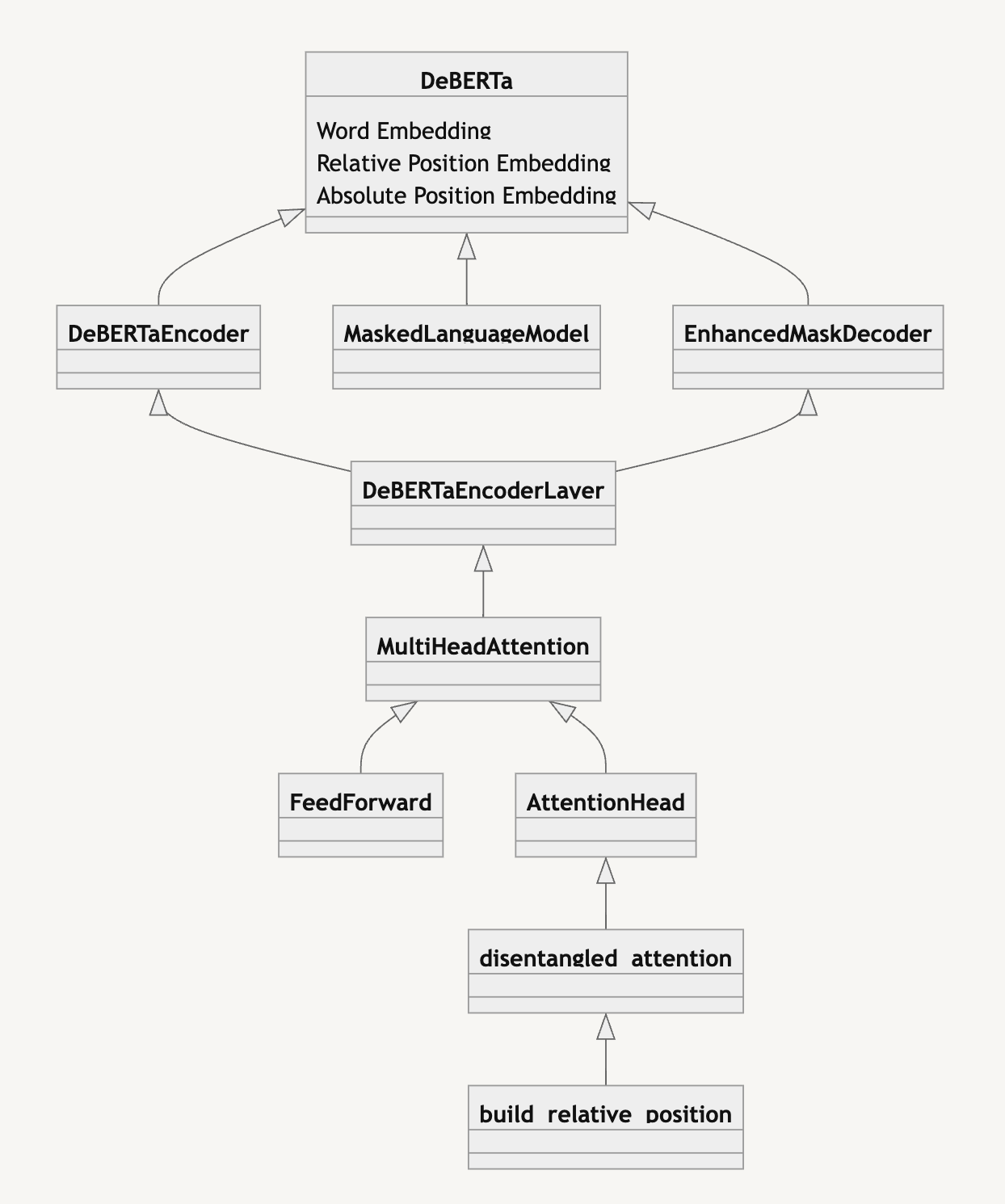 DeBERTa Class Diagram
DeBERTa Class Diagram
위 자료는 필자가 구현한 DeBERTa의 구조를 표현한 그림이다. 코드 리뷰에 참고하시면 좋을 것 같다 첨부했다. 가장 중요한 Disentangled-Attention과 EMD부터 살펴본 뒤, 나머지 객체에 대해서 살펴보자.
🪢 Disentangled Self-Attention
\[\tilde{A_{ij}} = Q_i^c•K_j^{cT} + Q_i^c•K_{∂(i,j)}^{rT} + K_j^c•Q_{∂(i,j)}^{rT} \\
Attention(Q_c,K_c,V_c,Q_r,K_r) = softmax(\frac{\tilde{A}}{\sqrt{3d_h}})*V_c\]
Disentangled Self-Attention은 저자가 퓨어한 Input Embedding 정보와 Relative Position 정보를 통합시키기 위해 고안한 변형 Self-Attention 기법이다. 기존의 Self-Attention과 다르게 Position Embedding을 Input Embedding와 더하지 않고 따로 사용한다. 즉, 같은 $d_h$ 공간에 Input Embedding과 Relative Position이라는 서로 다른 두 벡터를 맵핑하고 그 관계성을 파악해보겠다는 뜻이다.
Input과 Position 정보를 서로 주체적인 입장에서 한 번씩 내적한다고 해서 Disentangled라는 이름이 붙게 되었다. Transformer-XL, XLNet에 제시된 Cross-Attention과 매우 유사한 개념이다. 첫번째 수식에서 가장 마지막 항을 제외하면 Cross-Attention과 포착하는 정보가 동일하다고 저자 역시 밝히고 있으니 참고하자.
Disentangled Self-Attention 은 총 5가지 linear projection matrix를 사용한다. Input Embedding 을 출처로 하는 $Q^c, k^c, V^c$, 그리고 Position Embedding을 출처로 하는 $Q^r, K^r$이다. 첨자 $c,r$은 각각 content, relative 의 약자로 행렬의 출처를 뜻한다. 한편 행렬 아래 첨자에 써있는 $i,j$는 각각 현재 어텐션 대상 토큰의 인덱스와 그 나머지 토큰의 인덱스를 가리킨다. 그래서 $\tilde{A_{ij}}$는 [NxN] 크기 행렬(기존 어텐션에서 쿼리와 키의 내적 결과에 해당)의 $i$번째 행백터의 $j$번째 원소의 값을 의미한다. Input Embedding 정보와 Relative Position 정보를 따로 따로 관리하기 때문에 우리가 기존에 알고 있던 Self-Attention과는 사뭇 다른 수식이다. 이제부터 수식의 항 하나하나의 의미를 구체적인 예시와 함꼐 파헤쳐보자.
☺️ c2c matrix
content2content의 약자로 첫번째 수식 우변의 첫번째 항을 가리키는 말이다. 이름의 의미는 내적에 사용하는 두 행렬의 출처가 모두 Input Embedding 이라는 사실을 내포하고 있다. 기존에 알고 있던 Self-Attention 의 두번째 단계인 $Q•K^T$와 거의 동일한 의미를 담고 있는 항이라고 생각하면 될 것 같다. 완전히 같다고 할 수 없는 이유는 Absolute Position 정보가 빠진채로 내적했기 때문이다.
따라서 연산의 의미 역시 우리가 기존에 알고 있던 바와 동일하다. 혹시 행렬 $Q,K,V$와 Self-Attention가 내포하는 의미에 대해 자세히 궁금하신 분이라면 필자가 작성한 Transformer논문 리뷰를 보고 오시길 바란다. 그래도 어차피 뒤에 남은 두개의 항을 설명하려면 어차피 예시를 들어야 하기 때문에 c2c항에서부터 시작해보려 한다.
당신은 오늘 저녁 밥으로 차돌박이 된장 찌개, 삼겹살 그리고 후식으로 구운 달걀을 먹고 싶다. 집에 재료가 하나도 없지만 마트에 가기 귀찮으니 필요한 식자재를 남편에게 사오라고 시킬 생각이다. 당신은 그래서 필요한 재료 리스트를 적고 있다. 그렇다면 필요한 재료를 어떤 식으로 표현해서 적어줘야 남편이 가장 빠르고 정확하게 필요한 모든 식자재를 사올 수 있을까??
이것을 고민하는게 바로 행렬 $Q^c$와 linear projector 인 $W_{Q^c}$의 역할이다.예를 들어 같은 앞다리살이라도 구이용이 있고 찌개용이 있다. 달걀도 구운 달걀이 있고 날달걀이 있다. 정확히 용도를 적어주는게 남편 입장에서는 아내의 의도대로 정확하게 장을 보기 훨씬 편할 것이다.
한편, 내적은 본래 파라미터가 필요한 연산은 아니라서 실제 손실함수 오차 역전을 통해 최적화(학습)되는 대상은 바로 $W_{Q^c}$가 된다. 남편이 장을 빠르고 정확하게 보는데 과연 당신이 적어준 리스트만 영향을 미칠까??
아니다. 당신이 어떤 음식을 위해 어떤 재료가 필요한지 그 의도를 잘 적어주는 것도 중요하지만 실제 마트에 적혀 있는 상품명과 상품설명 역시 중요하다. 좀 억지스러운 예시처럼 보이긴 하지만 달걀의 경우 육안으로만 보면 이것이 구운 달걀인지 날달걀인지 구분할 수 없다. 그런데 마트에 별다른 설명없이 상품명으로 “달걀” 이라고만 적혀있다 생각해보자.
아무리 당신이 좋은 행렬 $Q^c$를 표현해줘도 남편이 날달걀을 사올 확률이 꽤나 높을 것이다. 이렇게 마트에 적혀있는 상품명과 상품설명이 바로 행렬 $K^c$에 대응된다. 그리고 물건을 사기 위해 당신이 적어준 식자재 리스트와 매장에 적힌 상품명과 상품설명을 대조하며 이것이 의도에 맞는 상품인지 따져보는 작업이 바로 $Q_i^c•K_j^{cT}$, c2c matrix가 된다.
다만, 전역 어텐션을 사용하기 때문에 달걀을 사기 위해 매장에 있는 모든 상품과 대조를 한다고 생각하면 된다. 특히 기존 전역 어텐션의 $Q_i^c•K_j^{cT}$의 경우 모든 상품과 대조하는 과정에서 대조군이 매장에 전시된 위치, 카테고리 분류상 어느 코너에 속하는지 등의 위치 정보를 한꺼번에 고려하지만, 우리의(c2c matrix) 경우 여기서 이런 위치 정보를 전혀 고려하지 않고 뒤에 두 개의 항에서 따로 고려한다.
정리하면, c2c는 매장에 진열된 식자재의 상품명 및 설명만 가지고 내가 사야 하는 식재료인지 아닌지 판단하는 작업을 수학적으로 모델링 했다고 볼 수 있겠다. 자연어 처리 맥락에서 바라보면, 특정 토큰의 의미를 알기 위해서 syntactical한 정보없이 순수하게 나머지 다른 토큰들의 의미를 가중합으로 반영하는 행위에 대응된다.
🗂️ c2p matrix
content2position의 약자로 수식 우변의 두번째 항, $Q_i^c•K_{∂(i,j)}^{rT}$를 가리킨다. c2c때와는 다르게 서로 출처가 다른 두 행렬을 사용해 c2p라는 이름을 붙였다. 내적 대상의 쿼리는 Input Embedding으로부터 만든 행렬 $Q_i^c$, 키는 Position Embedding으로부터 만든 행렬 $K_{∂(i,j)}^{rT}$ 을 사용했다. word context와 relative position을 서로 대조한다는 것이 무슨 의미를 갖는지 직관적으로 알기 힘드니 장보기 예시를 통해 이해해보자.
구운 달걀과 날달걀의 예시를 들면서 상품명과 설명이 장보기에 중요한 영향을 미친다고 언급했다. 하지만 상품명과 설명이 여전히 단순 “달걀”으로 적혀 있어도 우리는 이것을 구분해 낼 방법이 있다. 바로 주변에 진열된 상품이 무엇인지 살펴보는 것이다. “달걀” 바로 옆에 우유, 치즈, 생선, 정육과 같은 신선식품류가 배치되어 있다고 가정해보자. 우리는 우리 눈 앞에 있는 “달걀”이 날달걀이라고 기대해 봄직하다. 만약 “달걀” 옆에 쥐포, 말린 오징어, 육포, 과자 같은 간식류 상품들이 배치되어 있다면 어떨까?? 그럼 이 “달걀”은 충분히 구운 달걀이라고 해석해볼 수 있다. 이처럼 주위에 어떤 다른 상품들이 배치 되어 있는가를 통해 우리가 사려는 물건이 맞는지 대조해보는 행위가 바로 c2p 에 대응된다. 그렇다면 주위에 어떤 다른 상품들이 배치 되어 있는가 정보를 모아 놓은 것이 바로 $K_{∂(i,j)}^{rT}$가 된다.
🔬 p2c matrix
Disentangled Self-Attention이 여타 다른 어텐션 기법들과 가장 차별화되는 부분이다. 저자가 논문에서 가장 강조하는 부분이기도 하다. 사실 그런 것치고는 논문 속 설명이 상당히 불친절해 이해하기 참 난해한 개념이다. 이거 설명하고 싶어서 장보기 예시를 생각해내게 되었다. 다시 남편에게 줄 장보기 리스트를 작성하던 시점으로 돌아가보자.
오늘 저녁 메뉴는 차돌박이 된장찌개와 구운 삼겹살이다. 먼저 차돌박이 된장찌개를 만들려면 어떤 재료가 필요할까?? 차돌박이, 된장, 청양고추, 양파, 다진 마늘, 호박과 같은 식자재가 필요할 것이다. 그리고 삼겹살에 필요한 재료를 생각해보자. 생삼겹살과 잡내를 없애는데 필요한 후추와 소금 그리고 구워 먹을 통마늘이 필요하다고 당신은 생각했다. 그럼 이제 이것을 바탕으로 리스트를 작성할 것이다. 어떤 식으로 리스트를 작성하는게 가장 최적일까??
c2c, c2p 예시와 함께 생각해보면 알 수 있다. c2c에서는 같은 재료라도 그 용도에 따라서 사야할 품목이 달라진다고 언급한 바있다. c2p 에서는 정확한 설명이 없어도 주변에 나열된 품목들을 보면서 어떤 상품인지 유추가 가능하다고 했다. 이것을 합쳐보자. 만약 당신이 아래와 같은 순서로 리스트를 적었다고 가정해보겠다.
# 장보기 리스트 예시1
차돌박이, 된장, 마늘, 청양고추, 양파, 호박, 삼겹살, 후추, 소금
아까 필요한 품목을 나열했을 때 분명히 다진 마늘과 통마늘을 동시에 생각했었다. 근데 위처럼 리스트를 작성해서 남편에게 줬다면 남편은 어떤 마늘을 사올까?? 당연히 차돌박이와 된장 그리고 양파 사이에 마늘이 위치한 것을 보고 남편은 국물용 마늘이 필요하구나 싶어서 다진 마늘을 사올 것이다.
그렇다면 반대로 당신이 아래처럼 리스트를 작성했다고 생각해보자.
# 장보기 리스트 예시2
차돌박이, 된장, 청양고추, 양파, 호박, 삼겹살, 마늘, 후추, 소금
이번에는 삼겹살 구울 때, 같이 구워먹을 통마늘이 필요하구나를 남편이 느낄 수 있을 것이다. 한편 아래와 같은 상황이라면 어떨까??
# 장보기 리스트 예시3
차돌박이, 된장, 마늘, 청양고추, 양파, 호박, 삼겹살, 마늘, 후추, 소금
조금 센스가 있는 남편이라면 된장찌개 국물용 다진마늘과 삼겹살 구이용 통마늘이 동시에 필요하구나라고 유추하고 매장에서 다진마늘, 통마늘이라 써있는 품목을 찾아서 둘 다 사올 것이다. 물론 센스있는 아내라면 애초에 저렇게 애매하게 마늘이라고 2번 안적고 다진마늘, 통마늘이라고 용도를 함께 적어줬겠지만 말이다.
이러한 일련의 상황이 바로 p2c에 대응된다. 그렇다면 아내가 적어준 리스트에서 주변에 위치한 품목들에 따라서 포착되는 대상 품목의 용도나 쓰임새, 의미 등이 바로 행렬 $Q_{∂(i,j)}^{rT}$가 된다.
⚒️ DeBERTa Scale Factor
처음에 나열한 수식을 다시 보면 DeBERTa의 scale factor는 기존 Self-Attention 과 다르게 $\sqrt{3d_h}$를 사용한다. 이유가 뭘까?? 기존 방식은 softmax layer에 전달하는 행렬의 종류가 $Q•K^T$ 한 개다. DeBERTa의 경우는 3개를 전달하게 된다. 그래서 $d_h$앞에 3을 곱해준 것이다. official repo의 코드를 확인해보면 확실히 알 수 있는데, 어텐션에 사용하는 행렬 종류의 개수를 $d_h$앞에 곱해준다. 아래는 repo에 올라와 있는 코드의 일부를 발췌한 것이다.
# official Disentangled Self-Attention by microsoft from official repo
...중략...
def forward(self, hidden_states, attention_mask, return_att=False, query_states=None, relative_pos=None, rel_embeddings=None):
if query_states is None:
query_states = hidden_states
query_layer = self.transpose_for_scores(self.query_proj(query_states), self.num_attention_heads).float()
key_layer = self.transpose_for_scores(self.key_proj(hidden_states), self.num_attention_heads).float()
value_layer = self.transpose_for_scores(self.value_proj(hidden_states), self.num_attention_heads)
rel_att = None
# Take the dot product between "query" and "key" to get the raw attention scores.
scale_factor = 1
if 'c2p' in self.pos_att_type:
scale_factor += 1
if 'p2c' in self.pos_att_type:
scale_factor += 1
if 'p2p' in self.pos_att_type:
scale_factor += 1
👩💻 Implementation
이렇게 Disentangled Self-Attention에 대한 모든 내용을 살펴봤다. 실제 구현은 어떻게 해야 하는지 필자가 작성한 파이토치 코드와 함께 알아보자.
# Pytorch Implementation of DeBERTa Disentangled Self-Attention
def build_relative_position(x_size: int) -> Tensor:
""" Build Relative Position Matrix for Disentangled Self-attention in DeBERTa
Args:
x_size: sequence length of query matrix
Reference:
https://arxiv.org/abs/2006.03654
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/da_utils.py#L29
"""
x_index, y_index = torch.arange(x_size, device="cuda"), torch.arange(x_size, device="cuda") # same as rel_pos in official repo
rel_pos = x_index.view(-1, 1) - y_index.view(1, -1)
return rel_pos
def disentangled_attention(
q: Tensor,
k: Tensor,
v: Tensor,
qr: Tensor,
kr: Tensor,
attention_dropout: torch.nn.Dropout,
padding_mask: Tensor = None,
attention_mask: Tensor = None
) -> Tensor:
""" Disentangled Self-attention for DeBERTa, same role as Module "DisentangledSelfAttention" in official Repo
Args:
q: content query matrix, shape (batch_size, seq_len, dim_head)
k: content key matrix, shape (batch_size, seq_len, dim_head)
v: content value matrix, shape (batch_size, seq_len, dim_head)
qr: position query matrix, shape (batch_size, 2*max_relative_position, dim_head), r means relative position
kr: position key matrix, shape (batch_size, 2*max_relative_position, dim_head), r means relative position
attention_dropout: dropout for attention matrix, default rate is 0.1 from official paper
padding_mask: mask for attention matrix for MLM
attention_mask: mask for attention matrix for CLM
Math:
c2c = torch.matmul(q, k.transpose(-1, -2)) # A_c2c
c2p = torch.gather(torch.matmul(q, kr.transpose(-1 z, -2)), dim=-1, index=c2p_pos)
p2c = torch.gather(torch.matmul(qr, k.transpose(-1, -2)), dim=-2, index=c2p_pos)
attention Matrix = c2c + c2p + p2c
A = softmax(attention Matrix/sqrt(3*D_h)), SA(z) = Av
Notes:
dot_scale(range 1 ~ 3): scale factor for Q•K^T result, sqrt(3*dim_head) from official paper by microsoft,
3 means that use full attention matrix(c2c, c2p, p2c), same as number of using what kind of matrix
default 1, c2c is always used and c2p & p2c is optional
References:
https://arxiv.org/pdf/1803.02155
https://arxiv.org/abs/2006.03654
https://arxiv.org/abs/2111.09543
https://arxiv.org/abs/1901.02860
https://arxiv.org/abs/1906.08237
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/disentangled_attention.py
"""
BS, NUM_HEADS, SEQ_LEN, DIM_HEADS = q.shape
_, MAX_REL_POS, _, _ = kr.shape
scale_factor = 1
c2c = torch.matmul(q, k) # A_c2c, q: (BS, NUM_HEADS, SEQ_LEN, DIM_HEADS), k: (BS, NUM_HEADS, DIM_HEADS, SEQ_LEN)
c2p_att = torch.matmul(q, kr.permute(0, 2, 3, 1).contiguous())
c2p_pos = build_relative_position(SEQ_LEN) + MAX_REL_POS / 2 # same as rel_pos in official repo
c2p_pos = torch.clamp(c2p_pos, 0, MAX_REL_POS - 1).repeat(BS, NUM_HEADS, 1, 1).long()
c2p = torch.gather(c2p_att, dim=-1, index=c2p_pos)
if c2p is not None:
scale_factor += 1
p2c_att = torch.matmul(qr, k) # qr: (BS, NUM_HEADS, SEQ_LEN, DIM_HEADS), k: (BS, NUM_HEADS, DIM_HEADS, SEQ_LEN)
p2c = torch.gather(p2c_att, dim=-2, index=c2p_pos) # same as torch.gather(k•qr^t, dim=-1, index=c2p_pos)
if p2c is not None:
scale_factor += 1
dot_scale = torch.sqrt(torch.tensor(scale_factor * DIM_HEADS)) # from official paper by microsoft
attention_matrix = (c2c + c2p + p2c) / dot_scale # attention Matrix = A_c2c + A_c2r + A_r2c
if padding_mask is not None:
padding_mask = padding_mask.unsqueeze(1).unsqueeze(2) # for broadcasting: shape (BS, 1, 1, SEQ_LEN)
attention_matrix = attention_matrix.masked_fill(padding_mask == 1, float('-inf')) # Padding Token Masking
attention_dist = attention_dropout(
F.softmax(attention_matrix, dim=-1)
)
attention_matrix = torch.matmul(attention_dist, v).permute(0, 2, 1, 3).reshape(-1, SEQ_LEN, NUM_HEADS*DIM_HEADS).contiguous()
return attention_matrix
p2c 를 구하는 과정의 코드라인에 주목해보자. 논문에 기재된 수식($K_j^c•Q_{∂(i,j)}^{rT}$)과 다르게, 쿼리와 키의 순서를 뒤집었다. 그래서 torch.gather의 차원 매개변수 dim를 c2p의 상황과 다르게 -2로 초기화하게 되었다. 내적하는 항의 순서를 뒤집은 것으로 인해 우리가 추출하고 싶은 대상 값인 상대 위치 임베딩이 -2번째 차원에 위치 하게 되기 때문이다.
😷 Enhanced Mask Decoder
DeBERTa의 설계 목적은 2가지 위치 정보를 적절히 섞어서 최대한 풍부한 임베딩을 만드는 것이라고 했다. 상대 위치 임베딩은 Disentangled Self-Attention을 통해 포착한다는 것을 이제 알았다. 그럼 절대 위치 임베딩은 어떤 식으로 모델링해줘야 할까?? 그 물음에 답은 바로 EMD라 불리는 Enhanced Mask Decoder에 있다. EMD의 원리에 대해 공부하기 전에 왜 절대 위치 임베딩이 NLU에 필요한지 짚고 넘어가자.
위 문장은 저자가 논문에서 Absolute Position Embedding의 필요성을 역설할 때 사용한 예시 문장이다. 과연 상대 위치 임베딩만 사용해서 store와 mall의 차이를 잘 구별할 수 있을까 생각해보자. 앞서 우리는 상대 위치 임베딩을 대상 토큰과 그 나머지 토큰 사이의 위치 변화에 따라 발생하는 파생적인 맥락 정보를 담은 행렬이라고 정의한 바 있다. 다시 말해, 대상 토큰의 의미를 주변에 어떤 context가 있는지 파악해 통해 이해해보겠다는 것이다.
예시 문장을 다시 보자. 두 대상 단어 모두 주위에 비슷한 의미를 갖는 단어들이 위치해 있다. 이런 경우 상대 위치 임베딩만으로는 시퀀스 내부에서 store와 mall의 의미 차이를 모델이 명확하게 이해하기 매우 어려울 것이다. 현재 상황에서 두 단어의 뉘앙스 차이는 결국 문장의 주어냐 목적어냐 하는 syntactical한 정보에 의해서 결정된다. syntactical한 정보의 필요성은 바로 절대 위치 임베딩이 NLU에 꼭 필요한 이유에 대응된다.
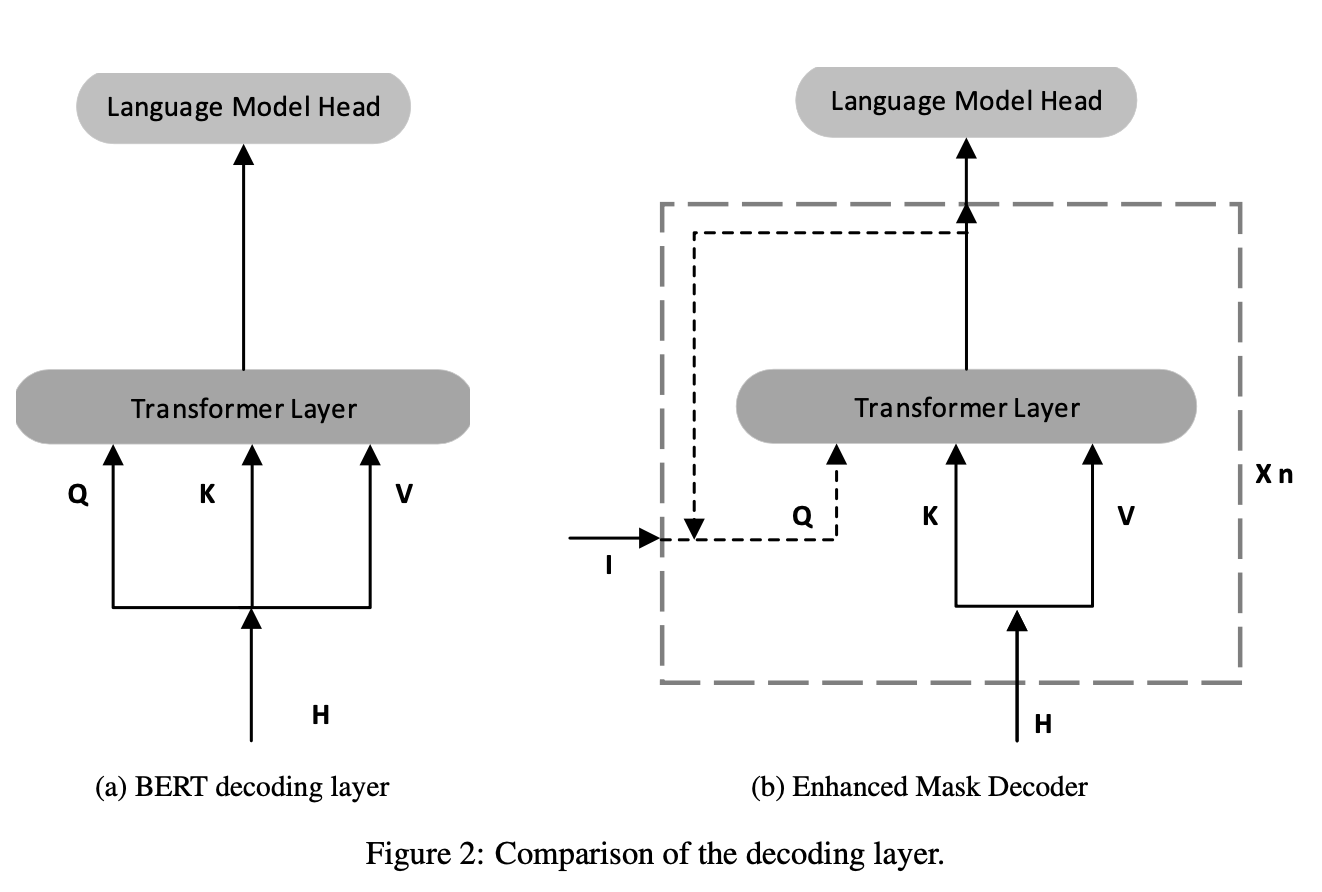 Enhanced Mask Decoder Overview
Enhanced Mask Decoder Overview
🤔 why named decoder
필자는 처음 논문을 읽었을 때 Decoder라는 이름을 보면서 참 의아했다. 분명 Only-Encoder 모델로 알고 있는데 어찌하여 이름에 디코더가 붙는 모듈이 있는 것인가. 그렇다고 이름을 저렇게 붙인 의도를 설명하는 것도 아니다. 그래서 필자가 스스로 추측해봤다.
DeBERTa는 pre-train task 로 MLM을 사용했다. MLM이 무엇인가?? 바로 마스킹된 자리에 적절한 토큰을 찾는 빈칸 채우기 문제다. 영미권에서는 이것을 denoising한다고 표현하기도 하는데, Absolute Position Embedding이 바로 이 denoising에 지대한 영향력을 미친다는 언급을 논문에서 찾아볼 수 있다. 따라서 denoising 성능에 큰 영향을 주는 Absolute Position Embedding을 활용한다고 해서 이름에 decoder를 붙였지 않았나 예상해본다.
논문에 같이 실린 그림을 통해서도 추측이 가능하다. EMD 의 구조를 설명하면서 옆에 BERT의 모식도도 함께 제공하는데, BERT에는 Decoder가 전혀 없다. 그런데도 이름을 BERT decoding layer라고 부르는 것보면 필자의 추측에 좀 더 정당성을 부여하는 것 같다.
(+ 추가) offical repo code에서도 EMD가 우리가 아는 그 Encoder를 사용한다는 사실을 확인할 수 있다.
🤷♂️ How to add Absolute Position
이제 EMD가 무엇이며, Absolute Position을 어떻게 모델에 추가하는지 알아보자. EMD는 MLM 성능을 높이기 위해 고안된 구조다. 그래서 토큰 예측을 위한 feedforward & softmax 레이어 직전에 쌓는다. 몇개의 EMD를 쌓을 것인지는 하이퍼파리미터이며, 저자의 실험 결과 2개 사용하는게 가장 효율적이라고 한다. 새롭게 인코더 블럭을 쌓지 않고 Disentangled-Attention 레이어의 가장 마지막 인코더 블럭과 가중치를 공유하는 형태로 구현한다.
# EMD Implementation Example
class EnhancedMaskDecoder(nn.Module):
def __init__(self, encoder: list[nn.ModuleList], dim_model: int = 1024) -> None:
super(EnhancedMaskDecoder, self).__init__()
self.emd_layers = encoder
class DeBERTa(nn.Module):
def __init__(self, vocab_size: int, max_seq: 512, N: int = 24, N_EMD: int = 2, dim_model: int = 1024, num_heads: int = 16, dim_ffn: int = 4096, dropout: float = 0.1) -> None:
# Init Sub-Blocks & Modules
self.encoder = DeBERTaEncoder(
self.max_seq,
self.N,
self.dim_model,
self.num_heads,
self.dim_ffn,
self.dropout_prob
)
self.emd_layers = [self.encoder.encoder_layers[-1] for _ in range(self.N_EMD)]. # weight share
self.emd_encoder = EnhancedMaskDecoder(self.emd_layers, self.dim_model)
따라서 N_EMD=2 로 설정한다는 것은 결국, Disentangled-Attention 레이어의 가장 마지막 인코더 블럭을 2개 더 쌓는 것과 동치다. 대신 인코더의 linear projection 레이어의 입력값이 다르다. Disentangled-Attention 의 행렬 $Q^c, K^c, V^c$는 이전 블럭의 hidden_states 값인 행렬 $H$를 입력으로, 행렬 $Q^r, K^r$은 레이어의 위치에 상관없이 모두 같은 값의 Relative Position Embedding 을 입력으로 사용한다.
반면, EMD 맨 처음 인코더 블럭의 행렬 $Q^c$는 바로 직전 블럭의 hidden_states 에 Absolute Position Embedding을 더한 값을 입력으로 사용한다. 이후 나머지 블럭에는 Disentangled-Attention 와 마찬가지로 이전 블럭의 hidden_states 를 사용한다. 행렬 $K^c, V^c$는 블럭 순서에 상관없이 이전 블럭의 hidden_states 만 가지고 linear projection을 수행한다. 그리고 행렬 $Q^r, K^r$ 역시 같은 값의 Relative Position Embedding 을 입력으로 사용한다.
사실 필자는 논문만 읽었을 때 EMD도 Relative Position 정보를 주입해 Disengtanled-Attention을 수행한다고 전혀 생각하지 못했다. 이는 논문의 설명이 상당히 불친절한 덕분인데, 논문에 이와 관련해서 자세한 설명도 없고 Absolute Position Embedding을 사용하는 레이어라서 당연히 일반적인 Self-Attention을 사용할 것이라고 생각했던 것이다.
필자는 여기서 Absolute Position이 왜 필요한지도 알겠고 그래서 행렬합으로 더해서 어텐션을 수행하는 것도 잘 알겠는데 왜 굳이 가장 마지막 레이어에서 이걸 할까?? 하는 의문이 들었다. 일반 Self-Attention처럼 맨 처음에 더하고 시작하면 안될까??
저자의 실험에 따르면 Absolute Position 을 처음에 추가하는 것보다 EMD처럼 가장 마지막에 더해주는게 성능이 더 좋았다고 한다. 그 이유로 Absolute Position를 초반에 추가하면 모델이 Relative Position을 학습하는데 방해가 되는 것 같다는 추측을 함께 서술하고 있다. 그렇다면 왜 방해가 되는 것일까??
필자의 뇌피셜이지만 이것 역시 blessing of dimensionality 에서 파생된 문제라고 생각한다. 일단 용어의 뜻부터 알아보자. blessing of dimensionality 란, 고차원 공간에서 무작위로 서로 다른 벡터 두개를 선택하면 두 벡터는 거의 대부분 approximate orthogonality를 갖는 현상을 설명하는 용어다. 무조건 성립하는 성질은 아니고 확률론적인 접근이라는 것을 명심하자. 아무튼 직교하는 두 벡터는 내적값이 0에 수렴한다. 즉, 두 벡터는 서로에게 영향을 미치지 못한다는 것이다.
이것은 Transformer에서 Input Embedding과 Absolute Position Embedding을 행렬합으로 더해도 좋은 학습 결과를 얻을 수 있는 이유가 된다. 다시 말해서, hidden states space 에서 Input Embedding 과 Absolute Position Embedding 역시 개별 벡터가 span 하는 부분 공간 끼리는 서로 직교할 가능성이 매우 높다는 것을 의미한다. 따라서 서로 다른 출처를 통해 만들어진 두 행렬을 더해도 서로에게 영향을 미치지 못할 것이고 그로 인해 모델이 Input과 Position 정보를 따로 잘 학습할 수 있을 것이라 기대해볼 수 있다.
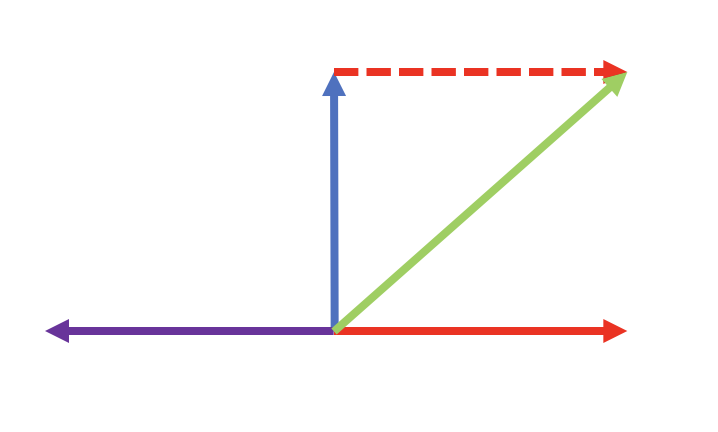 hidden states vector space example
hidden states vector space example
이제 다시 DeBERTa 경우로 돌아와보자. 위 그림의 파란색 직선을 Input Embedding, 빨간색 직선을 Absolute Position Embedding, 왼쪽의 보라색 직선을 Relative Position Embedding이라고 가정하자. blessing of dimensionality에 의해 word con text 정보(파란 직선)와 position 정보(빨강, 보라 직선)는 그림처럼 서로 근사 직교할 가능성이 매우 높다. 여기부터 필자의 뇌피셜이 들어가는데, 보라색 직선과 빨강색 직선은 성격이 좀 다르지만 결국 둘 다 시퀀스의 position 정보를 나타낸다는 점에서 뿌리는 같다고 볼 수 있다. 따라서 실제 hidden states 공간에서 어떤 식으로 맵핑될지는 잘 모르겠지만, 서로 직교하는 형태는 아닐 것이라 추측할 수 있다.
그렇다면 Absolute Position을 모델 극초반에 더해준다고 생각해보자. 인코더에 들어가는 행렬은 결국 위 그림의 초록색 직선으로 표현될 것이다. 파란색 직선과 빨간색 직선이 근사 직교한다는 가정하에 두 백터의 합은 두 벡터의 45도 정도 되는 곳에 위치하게(초록색 직선) 될 것이다. 그렇다면 보라색 직선과 초록색 직선의 관계 역시 근사 직교에서 서로 간섭하는 형태로 변화한다. 따서 EMD를 극초반에 사용하면 간섭이 발생해 모델이 Relative Position 정보를 제대로 학습하지 못할 것이다.
👩💻 Implementation
# Pytorch Implementation of DeBERTa Enhanced Mask Decoder
class EnhancedMaskDecoder(nn.Module):
"""
Class for Enhanced Mask Decoder module in DeBERTa, which is used for Masked Language Model (Pretrain Task)
Word 'Decoder' means that denoise masked token by predicting masked token
In official paper & repo, they might use 2 EMD layers for MLM Task
And this layer's key & value input is output from last disentangled self-attention encoder layer,
Also, all of them can share parameters and this layer also do disentangled self-attention
In official repo, they implement this layer so hard coding that we can't understand directly & easily
So, we implement this layer with our own style, as closely as possible to paper statement
Notes:
Also we temporarily implement only extract token embedding, not calculating logit, loss for MLM Task yet
MLM Task will be implemented ASAP
Args:
encoder: list of nn.ModuleList, which is (N_EMD * last encoder layer) from DeBERTaEncoder
References:
https://arxiv.org/abs/2006.03654
https://arxiv.org/abs/2111.09543
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/apps/models/masked_language_model.py
"""
def __init__(self, encoder: list[nn.ModuleList], dim_model: int = 1024) -> None:
super(EnhancedMaskDecoder, self).__init__()
self.emd_layers = encoder
self.layer_norm = nn.LayerNorm(dim_model)
def emd_context_layer(self, hidden_states, abs_pos_emb, rel_pos_emb, mask):
outputs = []
query_states = hidden_states + abs_pos_emb # "I" in official paper,
for emd_layer in self.emd_layers:
query_states = emd_layer(x=hidden_states, pos_x=rel_pos_emb, mask=mask, emd=query_states)
outputs.append(query_states)
last_hidden_state = self.layer_norm(query_states) # because of applying pre-layer norm
hidden_states = torch.stack(outputs, dim=0).to(hidden_states.device)
return last_hidden_state, hidden_states
def forward(self, hidden_states: Tensor, abs_pos_emb: Tensor, rel_pos_emb, mask: Tensor) -> tuple[Tensor, Tensor]:
"""
hidden_states: output from last disentangled self-attention encoder layer
abs_pos_emb: absolute position embedding
rel_pos_emb: relative position embedding
"""
last_hidden_state, emd_hidden_states = self.emd_context_layer(hidden_states, abs_pos_emb, rel_pos_emb, mask)
return last_hidden_state, emd_hidden_states
emd_context_layer 메서드에서 Absolute Position 정보를 추가해주는 부분을 제외하면 일반 Encoder 객체의 동작과 동일하다. 또한 DeBERTa는 모든 레이어가 같은 시점의 forward pass 때, 동일한 가중치의 Relative Position Embedding을 사용해야 하는데, EMD 역시 예외는 아니기 때문에 반드시 최상위 객체에서 초기화한 Relative Position Embedding을 똑같이 매개변수로 전달해줘야 한다.
그리고 마지막으로 객체에서 사용하는 emd_layers 는 모두 Disentangled-Attention 레이어의 가장 마지막 인코더라는 사실을 잊지 말자.
👩👩👧👦 Multi-Head Attention
이제 나머지 블럭들에 대해서 살펴보겠다. 원리나 의미는 이미 Transformer 리뷰에서 모두 살펴봤기 때문에 생략하고, 구현상 특이점에 대해서만 언급하려고 한다. 먼저 Single-Head Atttention 코드를 보자.
# Pytorch Implementation of Single Attention Head
class MultiHeadAttention(nn.Module):
""" In this class, we implement workflow of Multi-Head Self-attention for DeBERTa-Large
This class has same role as Module "BertAttention" in official Repo (bert.py)
In official repo, they use post-layer norm, but we use pre-layer norm which is more stable & efficient for training
Args:
dim_model: dimension of model's latent vector space, default 1024 from official paper
num_attention_heads: number of heads in MHSA, default 16 from official paper for Transformer
dim_head: dimension of each attention head, default 64 from official paper (1024 / 16)
attention_dropout_prob: dropout rate, default 0.1
Math:
attention Matrix = c2c + c2p + p2c
A = softmax(attention Matrix/sqrt(3*D_h)), SA(z) = Av
Reference:
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/2006.03654
"""
def __init__(self, dim_model: int = 1024, num_attention_heads: int = 12, dim_head: int = 64,
attention_dropout_prob: float = 0.1) -> None:
super(MultiHeadAttention, self).__init__()
self.dim_model = dim_model
self.num_attention_heads = num_attention_heads
self.dim_head = dim_head
self.fc_q = nn.Linear(self.dim_model, self.dim_model)
self.fc_k = nn.Linear(self.dim_model, self.dim_model)
self.fc_v = nn.Linear(self.dim_model, self.dim_model)
self.fc_qr = nn.Linear(self.dim_model, self.dim_model) # projector for Relative Position Query matrix
self.fc_kr = nn.Linear(self.dim_model, self.dim_model) # projector for Relative Position Key matrix
self.fc_concat = nn.Linear(self.dim_model, self.dim_model)
self.attention = disentangled_attention
self.attention_dropout = nn.Dropout(p=attention_dropout_prob)
def forward(self, x: Tensor, rel_pos_emb: Tensor, padding_mask: Tensor, attention_mask: Tensor = None,
emd: Tensor = None) -> Tensor:
""" x is already passed nn.Layernorm """
assert x.ndim == 3, f'Expected (batch, seq, hidden) got {x.shape}'
# size: bs, seq, nums head, dim head, linear projection
q = self.fc_q(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
k = self.fc_k(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 3, 1).contiguous()
v = self.fc_v(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
qr = self.fc_qr(rel_pos_emb).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
kr = self.fc_kr(rel_pos_emb).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head)
if emd is not None:
q = self.fc_q(emd).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
attention_matrix = self.attention(
q,
k,
v,
qr,
kr,
self.attention_dropout,
padding_mask,
attention_mask
)
attention_output = self.fc_concat(attention_matrix)
return attention_output
동작 자체는 동일하지만, 상대 위치 정보에 대한 linear projection 레이어가 추가 되었다. 그리고 Enhanced Mask Decoder 를 위해 forward 메서드에 조건문을 활용하여 Decoding하는 시점에는 hidden_states + absolute position embedding 으로 행렬 $Q^c$를 표현하게 구현했다. 이렇게 구현하면 EMD 를 위해 따로 AttentionHead를 구현할 필요가 없어서 코드 간소화가 된다.
MultiHeadAttention 객체는 단일 AttentionHead 객체를 호출할 때 rel_pos_emb 를 매개변수로 전달해야 한다는 점만 기억하면 된다.
🔬 Feed Forward Network
# Pytorch Implementation of FeedForward Network
class FeedForward(nn.Module):
"""
Class for Feed-Forward Network module in transformer
In official paper, they use ReLU activation function, but GELU is better for now
We change ReLU to GELU & add dropout layer
Args:
dim_model: dimension of model's latent vector space, default 512
dim_ffn: dimension of FFN's hidden layer, default 2048 from official paper
dropout: dropout rate, default 0.1
Math:
FeedForward(x) = FeedForward(LN(x))+x
"""
def __init__(self, dim_model: int = 512, dim_ffn: int = 2048, dropout: float = 0.1) -> None:
super(FeedForward, self).__init__()
self.ffn = nn.Sequential(
nn.Linear(dim_model, dim_ffn),
nn.GELU(),
nn.Dropout(p=dropout),
nn.Linear(dim_ffn, dim_model),
nn.Dropout(p=dropout),
)
def forward(self, x: Tensor) -> Tensor:
return self.ffn(x)
역시 기존 Transformer, BERT와 다른게 없다.
📘 DeBERTaEncoderLayer
# Pytorch Implementation of DeBERTaEncoderLayer(single Disentangled-Attention Encoder Block)
class DeBERTaEncoderLayer(nn.Module):
"""
Class for encoder model module in DeBERTa-Large
In this class, we stack each encoder_model module (Multi-Head Attention, Residual-Connection, LayerNorm, FFN)
This class has same role as Module "BertEncoder" in official Repo (bert.py)
In official repo, they use post-layer norm, but we use pre-layer norm which is more stable & efficient for training
References:
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/bert.py
"""
def __init__(self, dim_model: int = 1024, num_heads: int = 16, dim_ffn: int = 4096, dropout: float = 0.1) -> None:
super(DeBERTaEncoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(
dim_model,
num_heads,
int(dim_model / num_heads),
dropout,
)
self.layer_norm1 = nn.LayerNorm(dim_model)
self.layer_norm2 = nn.LayerNorm(dim_model)
self.dropout = nn.Dropout(p=dropout)
self.ffn = FeedForward(
dim_model,
dim_ffn,
dropout,
)
def forward(self, x: Tensor, pos_x: torch.nn.Embedding, mask: Tensor, emd: Tensor = None) -> Tensor:
""" rel_pos_emb is fixed for all layer in same forward pass time """
ln_x, ln_pos_x = self.layer_norm1(x), self.layer_norm1(pos_x) # pre-layer norm, weight share
residual_x = self.dropout(self.self_attention(ln_x, ln_pos_x, mask, emd)) + x
ln_x = self.layer_norm2(residual_x)
fx = self.ffn(ln_x) + residual_x
return fx
official code와 다르게 pre-layernorm 을 사용해 구현했다. pre-layernorm에 대해 궁금하다면 여기를 클릭해 확인해보자.
📚 DeBERTaEncoder
# Pytorch Implementation of DeBERTaEncoderr(N stacked DeBERTaEncoderLayer)
class DeBERTaEncoder(nn.Module, AbstractModel):
""" In this class, 1) encode input sequence, 2) make relative position embedding, 3) stack num_layers DeBERTaEncoderLayer
This class's forward output is not integrated with EMD Layer's output
Output have ONLY result of disentangled self-attention
All ops order is from official paper & repo by microsoft, but ops operating is slightly different,
Because they use custom ops, e.g. XDropout, XSoftmax, ..., we just apply pure pytorch ops
Args:
max_seq: maximum sequence length, named "max_position_embedding" in official repo, default 512, in official paper, this value is called 'k'
num_layers: number of EncoderLayer, default 24 for large model
Notes:
self.rel_pos_emb: P in paper, this matrix is fixed during forward pass in same time, all layer & all module must share this layer from official paper
References:
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/ops.py
"""
def __init__(
self,
cfg: CFG,
max_seq: int = 512,
num_layers: int = 24,
dim_model: int = 1024,
num_attention_heads: int = 16,
dim_ffn: int = 4096,
layer_norm_eps: float = 0.02,
attention_dropout_prob: float = 0.1,
hidden_dropout_prob: float = 0.1,
gradient_checkpointing: bool = False
) -> None:
super(DeBERTaEncoder, self).__init__()
self.cfg = cfg
self.max_seq = max_seq
self.num_layers = num_layers
self.dim_model = dim_model
self.num_attention_heads = num_attention_heads
self.dim_ffn = dim_ffn
self.hidden_dropout = nn.Dropout(p=hidden_dropout_prob) # dropout is not learnable
self.layer = nn.ModuleList(
[DeBERTaEncoderLayer(dim_model, num_attention_heads, dim_ffn, layer_norm_eps, attention_dropout_prob, hidden_dropout_prob) for _ in range(self.num_layers)]
)
self.layer_norm = nn.LayerNorm(dim_model, eps=layer_norm_eps) # for final-Encoder output
self.gradient_checkpointing = gradient_checkpointing
def forward(self, inputs: Tensor, rel_pos_emb: Tensor, padding_mask: Tensor, attention_mask: Tensor = None) -> Tuple[Tensor, Tensor]:
"""
Args:
inputs: embedding from input sequence
rel_pos_emb: relative position embedding
padding_mask: mask for Encoder padded token for speeding up to calculate attention score or MLM
attention_mask: mask for CLM
"""
layer_output = []
x, pos_x = inputs, rel_pos_emb # x is same as word_embeddings or embeddings in official repo
for layer in self.layer:
if self.gradient_checkpointing and self.cfg.train:
x = self._gradient_checkpointing_func(
layer.__call__, # same as __forward__ call, torch reference recommend to use __call__ instead of forward
x,
pos_x,
padding_mask,
attention_mask
)
else:
x = layer(
x,
pos_x,
padding_mask,
attention_mask
)
layer_output.append(x)
last_hidden_state = self.layer_norm(x) # because of applying pre-layer norm
hidden_states = torch.stack(layer_output, dim=0).to(x.device) # shape: [num_layers, BS, SEQ_LEN, DIM_Model]
return last_hidden_state, hidden_states
EMD와 마찬가지로 레이어의 위치에 상관없이 같은 시점에는 모두 동일한 Relative Position Embedding 을 사용해 linear projection 하도록 구현해주는 것이 중요 포인트다. forward 메서드를 확인하자!
🤖 DeBERTa
# Pytorch Implementation of DeBERTa
class DeBERTa(nn.Module, AbstractModel):
""" Main class for DeBERTa, having all of sub-blocks & modules such as Disentangled Self-attention, DeBERTaEncoder, EMD
Init Scale of DeBERTa Hyper-Parameters, Embedding Layer, Encoder Blocks, EMD Blocks
And then make 3-types of Embedding Layer, Word Embedding, Absolute Position Embedding, Relative Position Embedding
Args:
cfg: configuration.CFG
num_layers: number of EncoderLayer, default 12 for base model
this value must be init by user for objective task
if you select electra, you should set num_layers twice (generator, discriminator)
Var:
vocab_size: size of vocab in DeBERTa's Native Tokenizer
max_seq: maximum sequence length
max_rel_pos: max_seq x2 for build relative position embedding
num_layers: number of Disentangled-Encoder layers
num_attention_heads: number of attention heads
num_emd: number of EMD layers
dim_model: dimension of model
num_attention_heads: number of heads in multi-head attention
dim_ffn: dimension of feed-forward network, same as intermediate size in official repo
hidden_dropout_prob: dropout rate for embedding, hidden layer
attention_probs_dropout_prob: dropout rate for attention
References:
https://arxiv.org/abs/2006.03654
https://arxiv.org/abs/2111.09543
https://github.com/microsoft/DeBERTa/blob/master/experiments/language_model/deberta_xxlarge.json
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/config.py
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/deberta.py
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/bert.py
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/deberta/disentangled_attention.py
https://github.com/microsoft/DeBERTa/blob/master/DeBERTa/apps/models/masked_language_model.py
"""
def __init__(self, cfg: CFG, num_layers: int = 12) -> None:
super(DeBERTa, self).__init__()
# Init Scale of DeBERTa Module
self.cfg = cfg
self.vocab_size = cfg.vocab_size
self.max_seq = cfg.max_seq
self.max_rel_pos = 2 * self.max_seq
self.num_layers = num_layers
self.num_attention_heads = cfg.num_attention_heads
self.num_emd = cfg.num_emd
self.dim_model = cfg.dim_model
self.dim_ffn = cfg.dim_ffn
self.layer_norm_eps = cfg.layer_norm_eps
self.hidden_dropout_prob = cfg.hidden_dropout_prob
self.attention_dropout_prob = cfg.attention_probs_dropout_prob
self.gradient_checkpointing = cfg.gradient_checkpoint
# Init Embedding Layer
self.embeddings = Embedding(cfg)
# Init Encoder Blocks & Modules
self.encoder = DeBERTaEncoder(
self.cfg,
self.max_seq,
self.num_layers,
self.dim_model,
self.num_attention_heads,
self.dim_ffn,
self.layer_norm_eps,
self.attention_dropout_prob,
self.hidden_dropout_prob,
self.gradient_checkpointing
)
self.emd_layers = [self.encoder.layer[-1] for _ in range(self.num_emd)]
self.emd_encoder = EnhancedMaskDecoder(
self.cfg,
self.emd_layers,
self.dim_model,
self.layer_norm_eps,
self.gradient_checkpointing
)
def forward(self, inputs: Tensor, padding_mask: Tensor, attention_mask: Tensor = None) -> Tuple[Tensor, Tensor]:
"""
Args:
inputs: input sequence, shape (batch_size, sequence)
padding_mask: padding mask for MLM or padding token
attention_mask: attention mask for CLM, default None
"""
assert inputs.ndim == 2, f'Expected (batch, sequence) got {inputs.shape}'
word_embeddings, rel_pos_emb, abs_pos_emb = self.embeddings(inputs)
last_hidden_state, hidden_states = self.encoder(word_embeddings, rel_pos_emb, padding_mask, attention_mask)
emd_hidden_states = hidden_states[-self.cfg.num_emd]
emd_last_hidden_state, emd_hidden_states = self.emd_encoder(emd_hidden_states, abs_pos_emb, rel_pos_emb, padding_mask, attention_mask)
return emd_last_hidden_state, emd_hidden_states
Leave a comment