
🔪 [LoRA] Low-Rank Adaptation of Large Language Models
![]() Updated:
Updated:
🔭 Overview
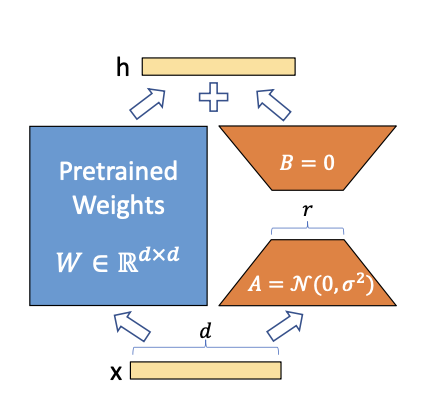
LoRA는 2021년 MS 연구진이 발표한 논문으로 원본(Full 파인튜닝)과 거의 유사한 성능(심지어 일부 벤치마크는 더 높음)으로 LLM 파인튜닝에 필요한 GPU 메모리를 획기적으로 줄이는데 성공해 주목을 받았다. 커뮤니티에서 LoRA is All You Need 라는 별명까지 얻으며 그 인기를 구가하고 있다.
DistilBERT 리뷰에서도 살펴보았듯, BERT와 GPT의 등장 이후, 모든 NLP 도메인에서 비약적인 성능 향상이 이뤄줬음에도 불구하고, NLP용 딥러닝 모델을 실생활에 활용하기에는 너무 큰 리소스 요구량과 레이턴시가 발목을 잡았다. 하지만 LoRA 발표 이후, 파인튜닝 시점에 훈련해야 하는 파라미터 수가 현저히 줄어들면서 모델의 체크포인트 용량이 기하급수적으로 감소했다. 덕분에 요구 GPU VRAM이 현저히 낮아져, 리소스 제한 때문에 서빙하지 못하는 경우가 많이 사라졌다. 그래서 오늘날 Mixed Precision, Quantization과 함께 모델 경량•최적화 분야에서 가장 중요한 주제로 떠오르고 있다.
내용을 살펴보기전, LoRA 는 이미 사전학습을 완료한 모델을 파인튜닝할 때 사용해야함을 다시 한 번 명심하자. 이번 포스팅에서는 두가지를 집중적으로 다룰 것이다.
1) 모델 크기 줄인 방법, 2) 크기를 줄이면서도 비슷한 성능을 낼 수 있었던 이유
🤔 Concept: Low-Rank Adaptation
\[h = W_0x + \Delta Wx = W_0x + BAx\]
아이디어는 상당히 간단하다. 사전학습을 마치고 수렴된 상태의 가중치 행렬을 의미하는 $W_0$과 새로운 가중치 행렬 $\Delta W$에 모두 입력을 통과시킨다. 그리고 나온 결과를 더해 다음층의 입력으로 사용한다. 오히려 새로운 가중치 행렬을 추가해 파인튜닝을 하는데 어떻게 훈련해야 하는 파라미터 수를 줄일 수 있었을까??
그 비밀은 Freeze(Stop Gradient, require_grad=False)와 Matrix Factorization에 숨어 있다. 먼저 사전 훈련된 가중치 행렬에 Freeze(Stop Gradient, require_grad=False) 를 적용해 그라디언트가 흐르지 않도록 한다. 이렇게 하면 파인튜닝 과정에서 가중치가 업데이트 되지 않아 사전 학습에서 습득한 지식을 유지할 수 있을 뿐만 아니라, 학습을 위해 그라디언트를 저장할 필요가 없어져 파인튜닝 때 필요한 GPU VRAM을 획기적으로 줄일 수 있다.
처음에 사전학습 가중치를 통과한 값과 새로운 가중치 행렬 $\Delta W$를 통과한 값을 서로 더한다고 언급했다. 그렇다면, 두 결과 행렬의 행렬 크기가 동일해야 한다는 것이다. 어떻게 기존보다 사이즈는 줄이면서 결과 행렬의 크기는 동일하게 만들어줄 수 있을까?? 바로 Low Rank value $r$을 도입해 Matrix Factorization 을 한다.
\[W_{d \times d} = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,d} \\ w_{2,1} & w_{2,2} & \cdots & w_{2,d} \\ \vdots & \vdots & \ddots & \vdots \\ w_{d,1} & w_{d,2} & \cdots & w_{d,d} \end{bmatrix}\]행렬 곱셈(matrix multiplication)을 다시 한 번 상기해보자. MxN 의 크기를 갖는 행렬에 NxK의 크기를 갖는 행렬을 곱해주면 MxK 의 크기를 갖는 행렬을 만들어줄 수 있다. 마찬가지다. dxd 크기인 사전학습의 가중치 행렬 $W_{d \times d}$과 크기를 맞추기 위해, dxd 짜리 행렬을 각각 dxr, rxd 의 크기를 갖는 두 행렬 $B, A$로 분해한다. 이 때, 행렬 $B$의 열차원과 행렬 $A$차원의 행차원 크기를 표현하는 $r$에 바로 Low Rank value $r$을 대입하면 된다.
$r=3$이라고 가정하고 768x768 짜리 기존 가중치 행렬 $W$과 768x3, 3x768의 크기를 갖는 $\Delta W = BA$의 파라미터 개수를 비교해보자. 계산해보면 전자는 589,824개, 후자는 4608개가 된다. 정확하게 128배 차이가 난다. 트랜스포머 모델 속에는 행렬 $W$과 같은 크기를 갖는 가중치 행렬이 단일 인코더 내부, 하나의 어텐션 레이어만 해도 4개($W_q, W_k, W_v, W_o$)가 있다. BERT-base 모델을 기준으로 보면, 해당 모델이 12개의 인코더로 구성되어 있으니까 총 48개의 가중치 행렬이 있고, 어림잡아도 48*128배의 학습 파라미터 감소 효과를 낼 수 있다. 모델의 레이어가 많으면 많을수록 더 좋은 효율을 보인다.
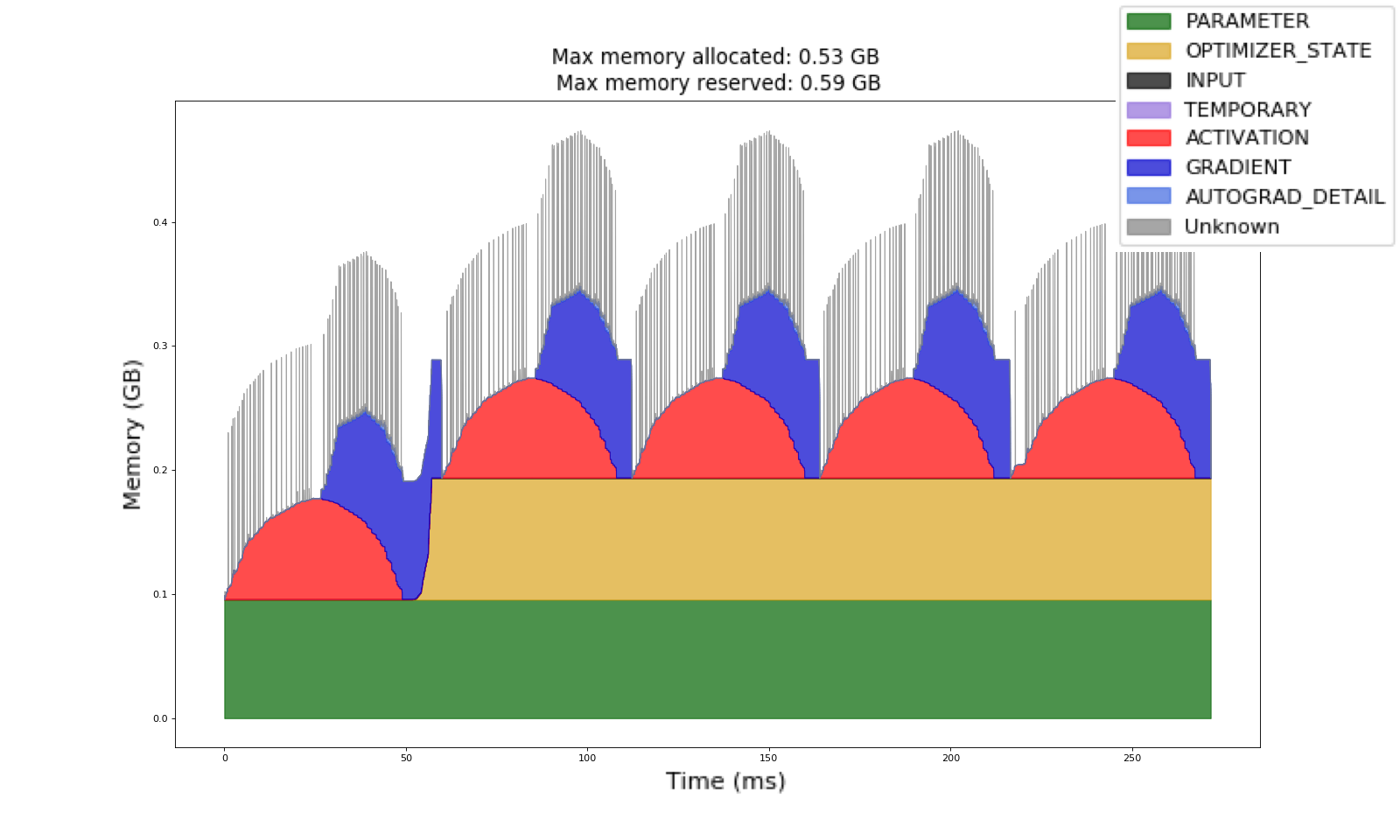
위 그림은 파이토치 공식 블로그에서 퍼온 자료로, 학습 때 ResNet50의 GPU VRAM 점유율 추이는 물론 모델의 개별 구성요소의 메모리 비율까지 자세히 보여준다. 먼저 Parameter와 Optimizer State를 보자. Parameter 는 모델에서 훈련을 통해 업데이트가 필요한 모든 구성 요소를 말한다. Freeze, require_grad=False @torch.no_grad() , torch.register_buffer() 의 영향을 받지 않은 모델 내부의 모든 텐서라고 보면 된다.
한편, Optimizer State 는 옵티마이저의 최적화 수행에 필요한 모든 정보들을 의미하는데, 예를 들어 업데이트 될 텐서의 메타 정보, 여러 하이퍼파라미터 값 같은 것들이 담겨 있다.
이 두 요소가 모델의 GPU VRAM을 차지하는 비율이 상당히 크다. 하지만 두 요소 모두 파라미터 개수에 비례하므로 LoRA 적용으로 파라미터 개수를 줄이면, GPU VRAM을 획기적으로 줄일 수 있다.
또한 파이토치는 역전파 수행을 위해 그라디언트를 파라미터와 동일한 모양(shape)을 갖는 텐서로 저장된다는 점을 감안하면, 기존의 Full-Rank 텐서 대신 Low-Rank 텐서를 학습에 이용함으로서 그라디언트 텐서의 크기 역시 획기적으로 줄일 수 있겠다.
트랜스포머 계열의 모델들이 ResNet 대비 압도적으로 파라미터 개수가 많기 때문에 LoRA를 적용한다면 훨씬 큰 효과를 볼 수 있을 것이다.


왼쪽 그림은 논문에서 제시한, BERT 계열의 LM에 LoRA를 적용한 파인튜닝 결과다. 표의 FT 가 일반적인 파인튜닝 방법에 의해 나온 결과다. 엎치락뒤치락하면서 거의 비슷한 양상을 보인다. 벤치마크 평균 성능은 LoRA가 더 높다. 아마, 적당히 성능 차이를 보여주기 위해 취사선택된 벤치마크일 가능성이 높지만, 그래도 상당히 유의미한 결과라고 생각한다. 우측은 GPT2에 LoRA를 적용한 결과다. 마찬가지로, 엇비슷한 성능 추이를 보여준다.
지금까지 LoRA 가 제시하는 방법론이 어떻게 획기적으로 학습 파라미터를 줄이고 나아가 모델이 차지하는 GPU VRAM 크기를 감소시켰는지 알아 보았다. 이제 LoRA를 적용해도 일반적인 파인튜닝 방법과 비슷한 성능을 유지할 수 있었는지 그 결과에 대해 해석해보자. 논문의 Chapter 7. UNDERSTANDIGN THE LOW-RANK UPDATES 내용에 해당된다. 해당 파트는 3가지 인사이트를 제시한다.
💡 Inisght 1. Apply to LoRA (Wq, Wv) or (Wq, Wk, Wv, Wo)
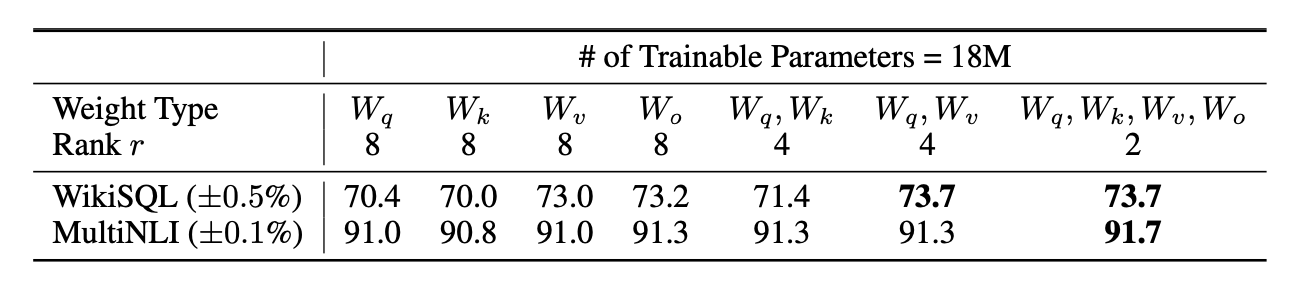
필자는 논문을 읽는 내내, ‘그래서 어떤 가중치 행렬에 적용해야 할까?? 모든 가중치 행렬에 적용해도 되는걸까??’하는 의문을 갖고 있었다. 근데 마침 저자들이 이러한 의문들을 에상한 듯, 위와 같이 적용 가중치 행렬에 따른 벤치마크 성능 결과를 표로 정리해주었다. 모델은 GPT3을 사용했다고 논문에서 밝히고 있다.
보이는 것과 같이, ($W_q, W_v$) 혹은 ($W_q, W_k, W_v, W_o$)에 LoRA를 적용하는게 가장 좋은 벤치마크 성능을 보여준다. 주목할 점은 랭크가 가장 낮으면서, 가장 많은 가중치 행렬에 LoRA를 적용하는게 가장 성능이 좋다는 것이다. 실험결과 제시 이외에 다른 증명이나 인사이트 제시가 없는게 아쉽지만, 이를 통해 다음과 같은 사실들을 떠올려 보았다.
- 1)
FT문제 해결에 필요한 문맥 정보들이쿼리,키,벨류행렬에 적절히 분산- 세가지 가중치 행렬이 모두 유의미한 문맥 표현을 학습
- 2) 낮은 랭크로도 충분히,
FT에 필요한 임베딩 추출 가능- 그만큼, 사전 학습에서 포착할 수 있는 임베딩이 풍부하며 일반화 능력이 좋다고 판단할 수 있음
- 사전 학습 단계에서 최대한 깊게 많이 학습시킬수록 FT 단계가 간소화 될 수 있지 않을까??
- 다만, 사전학습과 파인튜닝 사이의 괴리가 큰 경우라면??
- 사전 학습은 영어로, 파인튜닝은 한국어 데이터 세트로 하는 경우라면??
- 그만큼, 사전 학습에서 포착할 수 있는 임베딩이 풍부하며 일반화 능력이 좋다고 판단할 수 있음
마침 주석에 However, we do not expect a small r to work for every task or dataset. Consider the following thought experiment: if the downstream task were in a different language than the one used for pre-training, retraining the entire model 이라는 언급이 있는 것으로 보아, 랭크 값은 되도록 낮은 값을 선정하되, 사전학습과 파인 튜닝의 괴리가 심하다고 판단되는 경우, 높은 랭크값과 실험 결과 비교를 통해 적절한 값을 선정해야겠다.
💡 Inisght 2. 낮은 랭크로도 충분
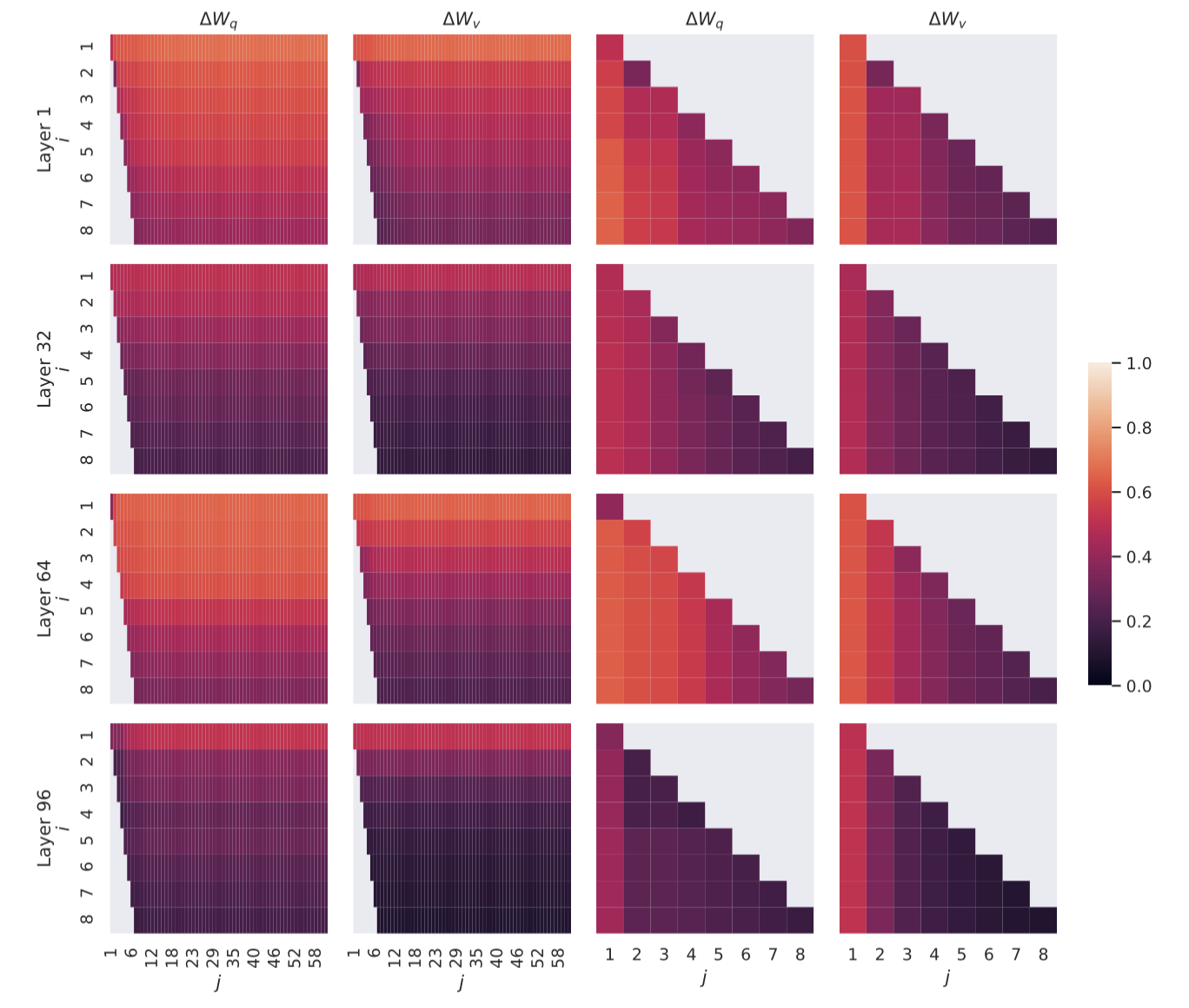
낮은 랭크로도 충분히, FT에 필요한 임베딩 추출 가능하다는 것을 좀 더 구체적인 실험으로 증명하고 있다. 그래프 $y$축과 $x$축은 각각 $A_r = 8$, $A_r = 64$인 (텐서 모양 [r, dim_model]) 가중치 행렬을 SVD하여 얻은 right-singular matrix 에서 top-i(1 ≤ i ≤ 8), top-j (1 ≤ j ≤ 64)개의 특이값을 추출한 뒤, Grassmann Distance를 거리 매트릭으로 이용해 부분 공간 사이의 유사도를 측정한 결과다.
한편, 왜 right-singular matrix 일까 다시 한 번 생각해봤다. 전체 벡터 공간에서 top-i(1 ≤ i ≤ 8), top-j (1 ≤ j ≤ 64)개의 특이값을 뽑아내 서로 비교하려면, 두 행렬 $A_{r = 8}$, $A_{r = 64}$이 같은 부분 공간에서 정의 되어야 한다. SVD 정의상, 왼쪽 특이벡터는 각각 8x8, 64x64차원이 되어 비교하기 어렵다. 한편, 오른쪽 벡터는 두 행렬 모두 dxd로 정의된다. 만약 행렬 $A$ 대신 $B$를 사용하고 싶다면 왼쪽 특이 벡터를 사용하면 된다.
오랜지 색에 가까울수록 서로 겹치는 정보가 많다는 의미를 갖는데, 사용한 인코더 위치와 상관없이 $A_{r = 8}$의 top 열벡터일수록, $A_{r = 64}$의 나머지 열벡터들과 높은 유사도(오랜지색에 가까움)을 기록하고 있다.(헷갈리니까 왼쪽 두 개 그래프만 보는게 낫다). 그리고 $A_{r = 8}$의 bottom 열벡터일수록, 거무죽죽한 색깔을 가지며 $A_{r = 64}$의 나머지 열벡터들과 낮은 유사도를 보인다.
결국 알고봤더니 사전학습을 충분히 수행한 모델의 경우, 파인튜닝 Task에 대해 적응시키는데 필요한 공간은 소수, 굳이 전체 공간을 학습 파라미터로 두고 파인튜닝해봐야 대부분의 열벡터는 쓰잘데기 없는 표현을 인코딩하는데 쓰이고 있었다고 볼 수 있겠다.
물론 여기서도 주의할 점은, GPT3의 사전학습과 궤가 비슷한 WikiSQL, MNLU에 대해 파인튜닝한 결과라는 점이다. 다국어로 구성된 데이터 세트를 활용하게 되면, 이 결과가 어떻게 바뀔지 모른다.
Grassmann Distance 는 선형 부분공간(linear subspace) 간의 거리를 측정하는 데 사용되는 개념이라고 하는데, 여기서 이것까지 다루면 포스팅 길이가 너무 길어질 것 같아서, 나중에 다른 포스트에서 다루도록 하겠다.
💡 Inisght 3. w ≠ delta w

사전 학습한 가중치 행렬 $W$과 LoRA 의 $\Delta W$가 서로 얼마나 유사한지, 실험적으로 증명하고 있다. 논문에서 제공한 실험 방식을 정리하면 다음과 같다.
- 1) 사전 학습으로 수렴된 쿼리 행렬, $W_q$를
task-specific한 공간($U^T, V^T$: $\Delta W$의Top-r개의Left, Right-Singular Vector)으로 투영 - 2) LoRA에 의해 수렴된 델타 쿼리행렬, $\Delta W_q$은 이미 행렬 전반에
task-specific한 정보를 담고 있음.- 그래서
top-r추출하지 않고 전체에 대해서프로베니우스 놈구하기
- 그래서
- 3) 1번 스탭에서 구한 투영 행렬, $U^TW_qV^T$에 대해
프로베니우스 놈계산 - 4) 2번/3번 수행:
task-specific한 공간을LoRA가 사전 학습 가중치에 비해 얼마나 많이 강조했는지 나타내는 지표- 논문에서는
Feature Amplication Factor라고 정의
- 논문에서는
프로베니우스 놈은 기하학적으로 행렬의 크기, 즉 선형변환의 크기를 의미한다. 그래서 곧 Feature Amplication Factor가 행렬의 크기/행렬의 크기를 나타내는 지표가 되고, 분자와 분모의 행렬은 모두 task-specific한 공간으로의 변환 크기를 의미하기 때문에, 같은 특징을 분자($\Delta W$)가 분모($W$)에 비해서 얼마나 더 강조하는지를 뜻하게 된다. 띠리서 factor 값이 클수록 LoRA가 사전 학습에서 강조하지 않았던 특징을 더욱 강조한다고 해석할 수 있게 된다. 이제 다시 표를 분석해보자.
Low Rank value $r=4$일 때, Feature Amplication Factor의 분모는 0.32, 분자는 6.91이 된다. 따라서 factor 값은 대략 21.5가 된다. 다시 말해 GPT3의 48번째 레이어의 경우, FT 적응에 필요한 task-specific한 공간을 LoRA가 사전학습 쿼리 행렬보다 21.5배 강조하고 있다는 것이다.
Low Rank value $r=64$일 때는 factor가 대략 1.9가 된다. $r=4$일 때보다 factor 값이 현저히 낮은 이유는 Insight 2의 결과(낮은 랭크로도 충분히 FT의 task-specific 정보 표현 가능)와 일맥상통한다고 볼 수 있다.
처음 읽었을 때 이 부분에 대한 해석이 너무 난해해, 저자들이 깃허브에 공개한, RoBERTa를 LoRA와 함께 MRPC 벤치마크에 파인튜닝한 가중치를 불러와 똑같은 방식으로 실험을 진행해봤다. 먼저 전체 실험 방식을 요약하면 다음과 같다.
- 1)
Huggingface Hub에서RoBERTa-base의 사전학습 가중치 불러오기 - 2)
LoRA official github에서roberta_base_lora_mrpc.bin불러오기 - 3)
1,2번에서 모두6번째인코더 레이어의쿼리 행렬에 대한 가중치 추출 - 4) 이하 나머지 과정은 위에 논문의 실험 방식을 따름
전체 과정을 코드로 정리하면 다음과 같다.
""" Insight 3 Experiment Code Exanple """
import torch
from transformers import AutoModel, AutoConfig
""" LoRA 결과 해석 재현 """
pt_config = AutoConfig.from_pretrained('FacebookAI/roberta-base')
pt_model = AutoModel.from_pretrained( # pretrained model
'roberta-base',
config=pt_config
)
lora_checkpoint = torch.load('model/roberta_base_lora_mrpc.bin', map_location='cpu')
lora_checkpoint
""" Select Wq in 6-th encoder layer """
pt_wq, lora_a, lora_b = pt_model.encoder.layer[6].attention.self.query.weight, lora_checkpoint['roberta.encoder.layer.6.attention.self.query.lora_A'], lora_checkpoint['roberta.encoder.layer.6.attention.self.query.lora_B']
delta_wq = lora_b @ lora_a
pt_wq.shape, lora_a.shape, lora_b.shape, delta_wq.shape
>>> (torch.Size([768, 768]),
>>> torch.Size([8, 768]),
>>> torch.Size([768, 8]),
>>> torch.Size([768, 768]))
""" Let's SVD, select top-r singular vector, 분자 """
U, S, V = torch.svd(delta_wq)
print(f"Delta W U: {U.shape}")
print(f"Delta W S: {S.shape}")
print(f"Delta W V: {V.shape}")
>>> Delta W U: torch.Size([768, 768])
>>> Delta W S: torch.Size([768])
>>> Delta W V: torch.Size([768, 768])
r = 4
r_U, r_V = U[:, :r], V[:r, :]
result1 = torch.matmul(r_U.T @ pt_wq, r_V.T)
fwq_norm = torch.norm(result1) # 분자값
result1, fwq_norm
>>> (tensor([[-0.0441, 0.0447, 0.0323, 0.0963],
[-0.0038, -0.0412, -0.0903, -0.0949],
[-0.0314, 0.1003, -0.0599, 0.0023],
[-0.0222, -0.1090, 0.0315, 0.0575]], grad_fn=<MmBackward0>),
>>> tensor(0.2539, grad_fn=<LinalgVectorNormBackward0>))
""" 분모 """
fdwq_norm = torch.norm(delta_wq) # 분모값
fdwq_norm
>>> tensor(5.0820)
"""결과: Feature Amplication Factor """
fdwq_norm / fwq_norm
>>> tensor(20.0170, grad_fn=<DivBackward0>)
👩💻 Implementation by Pytorch
import math
import torch
import torch.nn as nn
from torch import Tensor
class LoRA(nn.Module):
""" class module for Low-Rank adaptation of LLM SFT
This module return result of "BAx*(a/r)" in mathematical expression in official paper
Args:
dim: dimension of input tensor
rank: rank of tensor, which is hyperparameter for LoRA
alpha: hyperparameter for LoRA, trainable parameter, which is initialized by rank value
options: default str, 'rlora' which is already proved to work better than pure lora
you can select pure lora as passing argument 'lora'
Math:
h = W0x + ∆Wx = W0x + BAx*(a/r)
Notes:
we use sqrt(rank) value, it is already proven to work better in LoRA,
from Huggingface PEFT library official docs
References:
https://arxiv.org/abs/2106.09685
https://pytorch.org/blog/understanding-gpu-memory-1/
"""
def __init__(self, dim: int, rank: int, alpha: int, options: str = 'rlora'):
super().__init__()
self.a = nn.Parameter(torch.randn(rank, dim)) # init by random Gaussian distribution (normal distribution)
self.b = nn.Parameter(torch.zeros(dim, rank)) # init by zero
self.alpha = alpha / math.sqrt(rank) if options == 'rlora' else alpha / rank
def forward(self, inputs: Tensor) -> Tensor:
return torch.matmul(inputs, self.b @ self.a) * self.alpha
다음은 필자가 직접 구현한 LoRA 객체다. 구현상 특이점이라서 포스팅 내용에는 포함되지 않은 부분들이 있기 때문에 코드를 함께 살펴보자. 일단 행렬 $A$에 해당되는 self.a는 nn.Parameter를 호출해 모델이 학습 파라미터로 인식하도록 만든다. 그리고 논문에 나온대로, 랜덤 가우시안 분포를 따르도록 텐서를 초기화 해준다, 행렬 $B$에 해당되는 self.b nn.Parameter를 호출해 모델이 학습 파라미터로 사용하도록 만들고, 논문에 나온대로 영행렬로 초기화 해준다. 마지막으로 $\Delta W$ 값을 스케일링 해줄 스케일 팩터 alpha를 도입한다. 이때, options 인자를 통해 LoRA와 RLORA 중 어떤 것을 사용할지 선택할 수 있다. 이중에서, 분모의 랭크값에 제곱근을 취해주는 RLORA가 더 좋은 성능을 보인다고 후속 연구에서 밝혀졌다고 한다.
이렇게 LoRA 객체에 대해서 함께 살펴보았다. 구현 자체는 매우 간단하다. 하지만, 중요한 점은 사전 학습 모델의 가중치에 LoRA 객체를 적용하여 새로운 모델 객체를 만들어 내는 것이다. 아래 코드처럼,
""" before MHA """
q = self.fc_q(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
k = self.fc_k(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
v = self.fc_v(x).reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
attention_output = self.fc_concat(attention_matrix)
""" after MHA """
self.lora_q = lora()
self.lora_k = lora()
self.lora_v = lora()
self.lora_o = lora()
q = self.fc_q(x) + self.lora_q(x) # freeze + trainable
q.reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
k = self.fc_k(x) + self.lora_k(x) # freeze + trainable
k.reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
v = self.fc_v(x) + self.lora_v(x) # freeze + trainable
v.reshape(-1, x.shape[1], self.num_attention_heads, self.dim_head).permute(0, 2, 1, 3).contiguous()
attention_output = self.fc_concat(attention_matrix) + self.lora_o(attention_matrix) # freeze + trainable
선형 투영된 쿼리, 키, 벨류 행렬과 각각의 LoRA 객체를 더해줄 수만 있다면 매우 간단하게 해결될 문제지만, 사전학습 모델의 Multi-Head Attention객체를 처음부터 저런식으로 정의해야만 가능한 일이다. 필자가 작성한 모델 코드를 비롯해 대부분의 오픈소스로 풀려있는 트랜스포머 모델들은 저런식으로 작성되어 있지 않다. 따라서 다른 방법을 떠올려하는데, 당장은 너무 복잡한 작업이 될 것 같아(실험 어플리케이션 구조를 뒤엎어야 가능할 것으로 예측) 일단은 여기서 마무리하려고 한다. 만약 LoRA를 사전 학습 모델에 적용해 파인튜닝을 해보고 싶다면, Huggingface의 PEFT 라이브러리를 이용해보자. Hugginface의 Automodel, Trainer 객체와 유연하게 연동이 가능하다. 아래에 PEFT 공식 문서에서 참고한 Usage Example 코드를 첨부했으니 참고 부탁바란다.
""" PEFT LoRA Usage Example
Reference:
https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora/model.py
"""
>>> from transformers import AutoModelForSeq2SeqLM
>>> from peft import LoraModel, LoraConfig
>>> config = LoraConfig(
... task_type="SEQ_2_SEQ_LM",
... r=8, # rank value in official paper
... lora_alpha=32, # alpha value in official paper
... target_modules=["q", "v"],
... lora_dropout=0.01,
... )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
>>> lora_model = LoraModel(model, config, "default")
>>> import torch
>>> import transformers
>>> from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training
>>> rank = ...
>>> target_modules = ["q_proj", "k_proj", "v_proj", "out_proj", "fc_in", "fc_out", "wte"] # target for projection matrix, MLP
>>> config = LoraConfig(
... r=4, lora_alpha=16, target_modules=target_modules, lora_dropout=0.1, bias="none", task_type="CAUSAL_LM"
... )
>>> quantization_config = transformers.BitsAndBytesConfig(load_in_8bit=True)
>>> tokenizer = transformers.AutoTokenizer.from_pretrained(
... "kakaobrain/kogpt",
... revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
... bos_token="[BOS]",
... eos_token="[EOS]",
... unk_token="[UNK]",
... pad_token="[PAD]",
... mask_token="[MASK]",
... )
>>> model = transformers.GPTJForCausalLM.from_pretrained(
... "kakaobrain/kogpt",
... revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
... pad_token_id=tokenizer.eos_token_id,
... use_cache=False,
... device_map={"": rank},
... torch_dtype=torch.float16,
... quantization_config=quantization_config,
... )
>>> model = prepare_model_for_kbit_training(model)
>>> lora_model = get_peft_model(model, config)
Leave a comment