
🗂️[SpanBERT] SpanBERT: Improving Pre-training by Representing and Predicting Spans
![]() Updated:
Updated:
🔭 Overview
SpanBERT는 2020년 페이스북에서 발표한 BERT 계열 모델로, 새로운 방법론인 SBO(Span Boundary Objective)를 고안해 사전학습을 하여 기존 대비 높은 성능을 기록했다. 기존 MLM, CLM은 단일 토큰을 예측하는 방식을 사용하기 때문에 Word-Level Task에 아주 적합하지만 상대적으로 QA, Sentence-Similarity 같은 문장 단위 테스크에 그대로 활용하기에는 부족한 점이 있었다. 이러한 문제를 해결하기 위해 고안된 방법론이 바로 SBO다. SBO란, MLM과 비슷하지만, Span(절•구문) 단위로 마스킹하고 다시 Denoising을 하기 때문에, Sentence-Level Task에 속하는 Down-Stream Task를 위한 모델의 사전 훈련으로 적합하다.
정리하자면, SpanBERT 모델은 기존 BERT의 구조적 측면 개선이 아닌, 사전학습 방법에 대한 개선 시도라고 볼 수 있다. 따라서 어떤 모델이더라도, 인코더 언어 모델이라면 모두 SpanBERT 구조를 사용할 수 있으며, 기존 논문에서는 원본 BERT 구조를 사용했다. 그래서 본 포스팅에서도 BERT에 대한 설명 없이 SBO에 대해서만 다루려고 한다.
📚 SBO: Span Boundary Objective
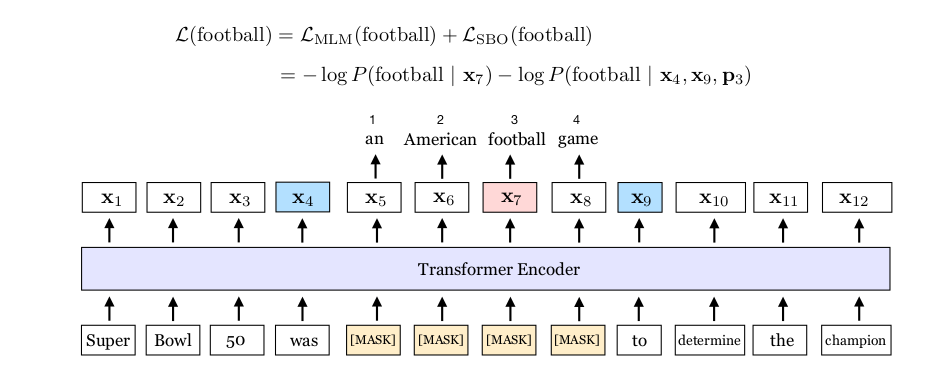
[SBO Algorithm Summary]
- 1) 연속된 범위의 Span 생성
- 무작위로 Span의 양쪽 끝 토큰 지정 ($x_{4}, x_{9}$)
- $x_{5}$ to $x_{8}$ 은 스팬 내부 토큰
- 마스킹 예산 계산
- 문장 당 마스킹 예산(합산 Span 길이)은 문장 길이의 15%
- 예시 시퀀스 길이: 512
- 마스킹 예산: 대략 75 = 512*0.15
- 기하 분포 사용해서 개별 스팬 길이 지정
- 개별 스팬당 최대 길이 지정, 최대 10이 넘지 않도록 설정
- 최대 스팬 합산 길이 도달까지 마스킹 반복
- 남은 마스킹 예산 < 현재 스팬 길이
- 남은 마스킹 예산을 현재 스팬 길이로 설정
- 남은 마스킹 예산 < 현재 스팬 길이
- 따라서 Subword Tokenizing이 아니라 Whole Word Masking 단위 작업이 필요
- 무작위로 Span의 양쪽 끝 토큰 지정 ($x_{4}, x_{9}$)
- 2) 시작 토큰 기준, 상대 위치 계산
- 스팬 내부 토큰의 상대 위치 임베딩 생성 및 계산
- 시작토큰, 마지막토큰, 스팬 내부 토큰의 상대 위치 임베딩을 concat, 은닉 벡터 생성
- SpanHead에 은닉 벡터 통과시키기
- 3) SpanHead 출력값을 마스킹에 대한 예측 표현으로 사용
SBO의 아이디어 자체는 상당히 간단하다. 기존 MLM처럼 무작위로 시퀀스에서 아무 토큰이나 선택하는게 아니라, 주어진 문장에서 일정 길이의 연속된 토큰들을 한번에 선택해 마스킹 처리하여 학습하겠다는 것이다. 논문에서 제시한 SBO 알고리즘을 정리하면 아래와 같다.
\[\begin{align*} h_0 &= [x_{s-1}; x_{e+1}; p_{i-s+1}] \\ h_1 &= \text{LayerNorm}(\text{GeLU}(W_1 h_0)) \\ y_i &= \text{LayerNorm}(\text{GeLU}(W_2 h_1)) \end{align*}\]위 그림을 예시로 알고리즘을 살펴보자. 먼저 주어진 스팬 길이에 맞게, 스팬의 시작과 끝 지점이 되는 토큰을 무작위로 선택한다. 그다음 시작 위치를 기준으로, 스팬 내부에 속하는 토큰들의 상대 위치 인덱스를 계산해준다. 그림 속 $x_{7}$ 토큰의 상대 위치 번호는 3이 된다. 미리 정의한 상대 위치 임베딩에서 행 인덱스가 3인 행벡터를 가져온다. 그 다음 양쪽 끝 벡터와 concat을 수행하여 $h_{0}$ 을 만든다. 그리고 미리 정의된 SBOHead에 통과시킨다. SBOHead에게 반환 받은 은닉 벡터값은 해당 위치의 마스킹에 대한 예측값($y_{i}$)으로 사용하고 이를 이용해 SBO 손실을 구한다. 지금까지 내용을 정리해 수식으로 표현하면 위와 같다.
SpanBERT의 목적함수는 SBO 손실 뿐만 아니라 기존 MLM 손실도 함꼐 포함되어 있다. 다만 MLM 손실을 구하기 위해 주어진 시퀀스에 대해 따로 마스킹을 하는 것은 아니고, SBO를 위해 적용했던 Span Masking을 그대로 활용한다. 대신 위의 SBO 수식의 $h_{0}$ 이 아니라, $x_{i-s+1}$ ($i-s+1$ 번째 토큰의 인코더 출력값)을 그대로 MLM 손실을 구하는데 사용한다. 정리하면, SpanBERT의 최종 손실은 위 수식과 같다. 한편, ELECTRA 때와는 다르게 두 손실의 스케일 차이가 거의 없어 따로 스케일 상수를 곱해주지는 않는 것 같다.
👩💻 Implementation by Pytorch
논문의 내용 종합하여 파이토치로 SpanBERT를 구현해봤다. 논문에 포함된 아이디어를 이해하는데는 어렵지 않았지만, 제한된 조건에 맞는 스팬을 찾고, 마스킹하는 과정을 실제 구현하는 것은 매우 까다로운 편이었다.
본 포스팅에서는 SpanBERT의 SBO 학습을 위한 입력 만들기, SBOHead에 대해서만 설명하려고 한다. BERT, Whole World Masking에 대해 궁금하다면 이전 포스팅을, 전체 모델 구조 대한 코드는 여기 링크를 통해 참고바란다.
공개할 코드는 아직 완벽하게 벡터화를 적용하지 못해, GPU 병렬 연산에 최적화 되지 못한 점 양해 부탁한다. 빠른 시일 이내에 벡터화를 적용해서 다시 수정된 코드를 올리겠다.
👩💻 Span Masking Algoritm
import random
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
from torch import Tensor
from typing import Dict, List, Tuple, Any
from ..tuner.mlm import WholeWordMaskingCollator
from configuration import CFG
BPE = [
'RobertaTokenizerFast',
'GPT2TokenizerFast',
]
SPM = [
'DebertaV2TokenizerFast',
'DebertaTokenizerFast',
'XLMRobertaTokenizerFast',
]
WORDPIECE = [
'BertTokenizerFast',
'ElectraTokenizerFast',
]
def random_non_negative_integer(max_value: int) -> int:
return random.randint(0, max_value)
class SpanCollator(WholeWordMaskingCollator):
""" Custom Collator for Span Boundary Objective Task, which is used for span masking algorithm
Span Masking is similar to Whole Word Masking, but it has some differences:
1) Span Masking does not use 10% of selected token left & 10% of selected token replaced other vocab token
- just replace all selected token to [MASK] token
Algorithm:
1) Select 2 random tokens from input tokens for spanning
2) Calculate relative position embedding for each token with 2 random tokens froms step 1.
3) Calculate span boundary objective with 2 random tokens from step 1 & pos embedding from step 2.
Args:
cfg: configuration.CFG
masking_budget: masking budget for Span Masking
(default: 0.15 => Recommended by original paper)
span_probability: probability of span length for Geometric Distribution
(default: 0.2 => Recommended by original paper)
max_span_length: maximum span length of each span in one batch sequence
(default: 10 => Recommended by original paper)
References:
https://arxiv.org/pdf/1907.10529.pdf
"""
def __init__(
self,
cfg: CFG,
masking_budget: float = 0.15,
span_probability: float = 0.2,
max_span_length: int = 10
) -> None:
super(SpanCollator, self).__init__(cfg)
self.cfg = cfg
self.tokenizer = self.cfg.tokenizer
self.masking_budget = masking_budget
self.span_probability = span_probability
self.max_span_length = max_span_length
def _whole_word_mask(
self,
input_tokens: List[str],
max_predictions: int = CFG.max_seq
) -> List[int]:
"""
0) apply Whole Word Masking Algorithm for make gathering original token index in natural language
1) calculate number of convert into masking tokens with masking budget*len(input_tokens)
2) define span length of this iteration
- span length follow geometric distribution
- span length is limited by max_span_length
"""
cand_indexes = []
for i, token in enumerate(input_tokens):
if token == "[CLS]" or token == "[SEP]":
continue
if len(cand_indexes) >= 1 and self.select_post_string(token): # method from WholeWordMaskingCollator
cand_indexes[-1].append(i)
elif self.select_src_string(token): # method from WholeWordMaskingCollator
cand_indexes.append([i])
l = len(input_tokens)
src_l = len(cand_indexes)
num_convert_tokens = int(self.masking_budget * l)
budget = num_convert_tokens # int is immutable object, so do not copy manually
masked_lms = []
covered_indexes = set()
while budget:
span_length = max(1, min(10, int(torch.distributions.Geometric(probs=self.span_probability).sample())))
src_index = random_non_negative_integer(src_l - 1)
if span_length > budget:
if budget < 5: # Set the span length to budget to avoid a large number of iter if the remaining budget is too small
span_length = budget
else:
continue
if cand_indexes[src_index][0] + span_length > l - 1: # If the index of the last token in the span is outside the full sequence range
continue
if len(cand_indexes[src_index]) > span_length: # handling bad case: violating WWM algorithm at start
continue
span_token_index = cand_indexes[src_index][0] # init span token index: src token
while span_length:
if span_length == 0:
break
if span_token_index in covered_indexes: # If it encounters an index that is already masked, it ends, and starts the next iteration
break
else:
covered_indexes.add(span_token_index)
masked_lms.append(span_token_index)
span_length -= 1
budget -= 1
span_token_index += 1
continue
if len(covered_indexes) != len(masked_lms):
raise ValueError("Length of covered_indexes is not equal to length of masked_lms.")
mask_labels = [1 if i in covered_indexes else 0 for i in range(len(input_tokens))]
return mask_labels
def get_mask_tokens(
self,
inputs: Tensor,
mask_labels: Tensor
) -> Tuple[Tensor, Tensor]:
""" Prepare masked tokens inputs/labels for Span Boundary Objective with MLM (15%),
All of masked tokens (15%) are replaced by [MASK] token,
Unlike BERT MLM which is replaced by random token or stay original token left
"""
labels = inputs.clone()
probability_matrix = mask_labels
special_tokens_mask = [
self.tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
if self.tokenizer.pad_token is not None:
padding_mask = labels.eq(self.tokenizer.pad_token_id)
probability_matrix.masked_fill_(padding_mask, value=0.0)
masked_indices = probability_matrix.bool()
labels[~masked_indices] = -100 # We only compute loss on masked tokens
inputs[masked_indices] = self.tokenizer.convert_tokens_to_ids(self.tokenizer.mask_token)
return inputs, labels
def forward(self, batched: List[Dict[str, Tensor]]) -> Dict:
""" Abstract Method for Collator, you must implement this method in child class """
input_ids = [torch.as_tensor(x["input_ids"]) for x in batched]
padding_mask = [self.get_padding_mask(x) for x in input_ids]
padding_mask = pad_sequence(padding_mask, batch_first=True, padding_value=True)
input_ids = pad_sequence(input_ids, batch_first=True, padding_value=0)
mask_labels = []
for x in batched:
ref_tokens = []
for input_id in x["input_ids"]:
token = self.tokenizer._convert_id_to_token(input_id)
ref_tokens.append(token)
mask_labels.append(self._whole_word_mask(ref_tokens))
mask_labels = [torch.as_tensor(x) for x in mask_labels]
mask_labels = pad_sequence(mask_labels, batch_first=True, padding_value=0)
input_ids, labels = self.get_mask_tokens(
input_ids,
mask_labels
)
return {
"input_ids": input_ids,
"labels": labels,
"padding_mask": padding_mask,
"mask_labels": mask_labels
}
👩💻 SBO Head
class SBOHead(nn.Module):
""" Custom Head for Span Boundary Objective Task, this module return logit value for each token
we use z for class logit, each Fully Connected Layer doesn't have bias term in original paper
so we don't use bias term in this module => nn.Linear(bias=False)
You must select option for matrix sum or concatenate with x_s-1, x_e+1, p_i-s+1
If you select concatenate option, you must pass is_concatenate=True to cfg.is_concatenate, default is True
Math:
h_0 = [x_s-1;x_e+1;p_i-s+1]
h_t = LayerNorm(GELU(W_0•h_0))
z = LayerNorm(GELU(W_1•h_t))
Args:
cfg: configuration.CFG
is_concatenate: option for matrix sum or concatenate with x_s-1, x_e+1, p_i-s+1, default True
max_span_length: maximum span length of each span in one batch sequence
(default: 10 => Recommended by original paper)
References:
https://arxiv.org/pdf/1907.10529.pdf
"""
def __init__(
self,
cfg: CFG,
is_concatenate: bool = True,
max_span_length: int = 10
) -> None:
super(SBOHead, self).__init__()
self.cfg = cfg
self.is_concatenate = is_concatenate # for matrix sum or concatenate with x_s-1, x_e+1, p_i-s+1
self.projector = nn.Linear(self.cfg.dim_model, self.cfg.dim_model*3, bias=False) # for concatenate x_s-1, x_e+1, p_i-s+1
self.span_pos_emb = nn.Embedding(max_span_length*3, cfg.dim_model) # size of dim_model is research topic
self.head = nn.Sequential(
nn.Linear(self.cfg.dim_model*3, self.cfg.dim_ffn),
nn.GELU(),
nn.LayerNorm(self.cfg.dim_ffn),
nn.Linear(self.cfg.dim_ffn, self.cfg.dim_model, bias=False),
nn.GELU(),
nn.LayerNorm(self.cfg.dim_model),
)
self.classifier = nn.Linear(self.cfg.dim_model, self.cfg.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(cfg.vocab_size)) # for matching vocab size
self.classifier.bias = self.bias
@staticmethod
def find_consecutive_groups(mask_labels: Tensor, target_value: int = 1) -> List[List[Dict]]:
""" Get the start and end positions of consecutive groups in tensor for the target value
This method is used for SBO Objective Function, this version is not best performance to make span groups
Args:
mask_labels: masking tensor for span
target_value: target value for finding consecutive groups
"""
all_consecutive_groups = []
for mask_label in mask_labels:
consecutive_groups = []
current_group = None
for i, value in enumerate(mask_label):
if value == target_value:
if current_group is None:
current_group = {"start": i, "end": i}
else:
current_group["end"] = i
else:
if current_group is not None:
consecutive_groups.append(current_group)
current_group = None
if current_group is not None:
consecutive_groups.append(current_group)
all_consecutive_groups.append(consecutive_groups)
return all_consecutive_groups
def cal_span_emb(self, h: Tensor, hidden_states: Tensor, consecutive_groups: List[List[Dict]]) -> Tensor:
""" Calculate span embedding for each span in one batch sequence
Args:
h: hidden states, already passed through projection layer (dim*3)
hidden_states: hidden states from encoder
consecutive_groups: consecutive groups for each batch sequence
"""
for i, batch in enumerate(consecutive_groups): # batch level
for j, span in enumerate(batch): # span level
start, end = span["start"], span["end"]
length = end - start + 1
idx = torch.arange(length, device=self.cfg.device) # .to(self.cfg.device)
context_s, context_e = hidden_states[i, start - 1, :], hidden_states[i, end + 1, :]
span_pos_emb = self.span_pos_emb(idx).squeeze(0)
if length > 1:
for k, p_h in enumerate(span_pos_emb): # length of span_pos_emb == length of span of this iterations
h[i, start+k, :] = torch.cat([context_s, p_h, context_e], dim=0)
else:
h[i, start, :] = torch.cat([context_s, span_pos_emb, context_e], dim=0)
return h
def forward(self, hidden_states: Tensor, mask_labels: Tensor) -> Tensor:
consecutive_groups = self.find_consecutive_groups(mask_labels) # [batch, num_consecutive_groups]
h = self.projector(hidden_states) # [batch, seq, dim_model*3]
h_t = self.cal_span_emb(h, hidden_states, consecutive_groups)
z = self.head(h_t)
logit = self.classifier(z)
return logit
Leave a comment