
👮 [ELECTRA] Pre-training Text Encoders as Discriminators Rather Than Generators
![]() Updated:
Updated:
🔭 Overview
ELECTRA는 2020년 Google에서 처음 발표한 모델로, GAN(Generative Adversarial Networks) Style 아키텍처를 NLP에 적용한 것이 특징이다. 새로운 구조 차용에 맞춰서 RTD(Replace Token Dection) Task를 고안에 사전 학습으로 사용했다. 모든 아이디어는 기존 MLM(Masked Language Model)을 사전학습 방법론으로 사용하는 인코더 언어 모델(BERT 계열)의 단점으로부터 출발한다.
[MLM 단점]
- 1) 사전학습과 파인튜닝 사이 불일치
- 파인튜닝 때 Masking Task가 없음
- 2) 연산량 대비 학습량은 적은편
- 전체 시퀀스의 15%만 마스킹 활용(15%만 학습)
- 전역 어텐션의 시공간 복잡도 고려하면 상당히 비효율적인 수치
- 시퀀스길이 ** 2의 복잡도
- Vocab Size만큼의 차원을 갖는 소프트맥스 계산 반복
그래서 MLM은 활용하되, 파인튜닝과 괴리는 크지 않은 목적함수를 설계함으로서 입력된 전체 시퀀스에 대해서 모델이 학습하여 연산량 대비 학습량을 늘리고자 했던게 바로 ELECTRA 모델이다.
정리하자면, ELECTRA 모델은 기존 BERT의 구조적 측면 개선이 아닌, 사전학습 방법에 대한 개선 시도라고 볼 수 있다. 따라서 어떤 모델이더라도, 인코더 언어 모델이라면 모두 ELECTRA 구조를 사용할 수 있으며, 기존 논문에서는 원본 BERT 구조를 사용했다. 그래서 본 포스팅에서도 BERT에 대한 설명 없이 RTD에 대해서만 다루려고 한다.
👮 RTD: New Pre-train Task
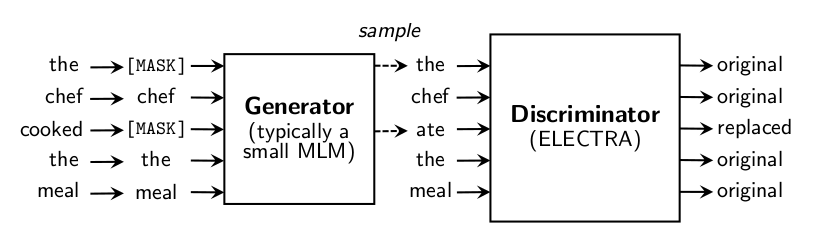
RTD의 아이디어는 간단하다. 생성자(Generator)가 출력으로 내놓은 토큰 시퀀스에 대해서 판별자(Discriminator)가 개별 토큰들이 원본인지 아닌지를 판정(이진 분류)하도록 만든다. 생성자는 기존의 MLM을 그대로 수행하고, 판별자는 생성자의 예측에 대해 진짜인지 가짜인지 분류하는 식이다.
위 그림을 예시로 살펴보자. 모델에 입력으로 the chef cooked the meal라는 시퀀스 준다. 그러면 MLM 규칙에 따라서 15%의 토큰이 무작위로 선택된다. 그래서 the, cooked가 마스킹 되었다. 이제 생성자는 마스킹 토큰에 대해 the, ate라는 결과를 내놓는다. 그래서 최종적으로 생성자가 반환하는 시퀀스는 the chef ate the meal이 된다. 이제 생성자가 반환한 시퀀스를 판별자에 입력으로 대입한다. 판별자는 개별 토큰들이 원본인지 아닌지를 판정해 결과를 출력한다.
이러한 구조 및 사전학습 방식의 장점은 판별자가 MLM 학습에 따른 지식을 생성자로부터 전수 받는 동시에 전체 시퀀스에 대해서 학습할 기회가 생긴다는 것이다. 시퀀스 내부 모든 토큰에 대해서 예측을 수행하고 손실을 계산할 수 있기 때문에 같은 크기의 시퀀스를 사용해도 기존 MLM 대비 더 풍부한 문맥 정보를 모델이 포착할 수 있게 된다. 또한 판별자를 파인튜닝의 BackBone으로 사용하면, 판별자의 사전학습은 결국 마스킹 없이 모든 시퀀스를 활용한 이진 분류라고 볼 수 있기 때문에, 사전학습과 파인튜닝 사이의 괴리도 상당히 많이 줄어들게 된다.
🌟 Architecture
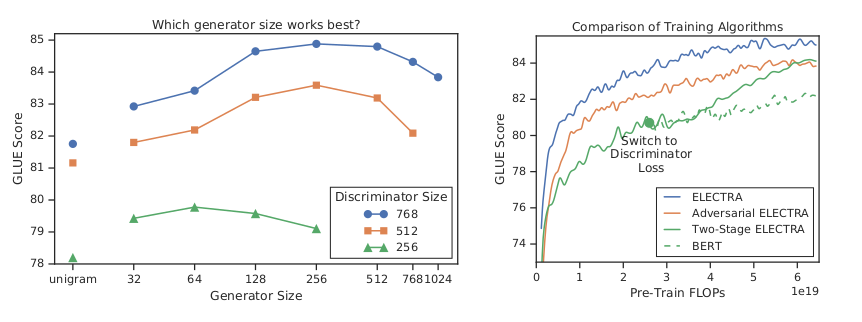
저자는 위와 같은 실험 결과를 바탕으로, 생성자의 width (은닉층) 크기가 판별자보다 작도록 모델 크기를 세팅하는게 가장 효율적이라고 주장한다. 제시된 그래프는 생성자와 판별자의 크기 변화 대비 파인튜닝 성능의 추이를 나타낸다. 생성자의 width 크기가 256, 판별자의 width 크기가 768일 때 가장 점수가 높다. depth(레이어 개수)에 대한 언급은 따로 없지만, 저자에 의해 공개된 Hyper-Param 테이블을 보면 은닉층의 크기만 줄이고, 레이어 개수는 생성자와 판별자가 같은 것으로 추정된다.
추가로, 생성자와 판별자가 임베딩 층을 서로 공유하는게 가장 높은 성능을 낸다고 주장한다. 오른쪽 그래프 추이를 보면 같은 연산량이라면, 임베딩 공유(파란색 실선) 방식이 가장 높은 파인튜닝 성능을 보여준다는 것을 알 수 있다. 따라서 단어 임베딩, 절대 위치 임베딩을 서로 공유하도록 설계한다. 대신 생성자 은닉층의 크기가 더 작은게 유리하다고 언급했기 때문에, 이것을 실제로 구현하려면 임베딩 층으로부터 나온 결과값을 생성자의 은닉층 차원으로 선형 투영해줘야 한다. 그래서 생성자의 임베딩 층과 인코더 사이에 linear layer가 추가되어야 한다.
\[\min_{\theta_G, \theta_D}\sum_{x \in X} \mathcal{L}_{\text{MLM}}(x, \theta_G) + \lambda \mathcal{L}_{\text{Disc}}(x, \theta_D)\]따라서, 지금까지 살펴본 모든 내용을 종합해보면 ELECTRA의 목적함수는 다음 수식과 같다. 생성자의 MLM 손실과 판별자의 이진 분류 손실을 더해서 모델에 오차 역전해주면 되는데, 특이한 점은 판별자의 손실에 상수값인 람다가 곱해진다는 것이다. 실제 모델을 구현하고 사전학습을 해보면, 데이터의 양이나 모델 크기 혹은 종류에 따라 달라지겠지만 두 손실 사이의 스케일의 차이가 10배정도 차이 나게 된다. 두 손실의 스케일을 맞춰주는 동시에, 임베딩층의 학습이 판별자의 손실을 줄이는데 더 집중하도록 만들기 위해 도입한 것으로 추정된다. 논문과 코드를 보면 저자는 $\lambda=50$ 으로 두고 학습하고 있다.
👩💻 Implementation by Pytorch
논문의 내용과 저자가 직접 공개한 코드를 종합하여 파이토치로 ELECTRA를 구현해봤다. 두 개의 서로 다른 모델을 같은 스탭에서 학습시켜야 하기 때문에, 제시된 내용에 비해 실제 구현은 매우 까다로운 편이었다. 본 포스팅에서는 ELECTRA 모델 구조를 비롯해 RTD 학습 파이프라인 구성에 필수적인 요소 몇 가지에 대해서만 설명하려 한다. 전체 구조에 대한 코드는 여기 링크를 통해 참고 부탁드린다.
ELECTRA의 사전 학습인 RTD의 학습 파이프라인을 구현한 코드를 본 뒤, 세부 구성 요소들에 대해서 살펴보자.
🌆 RTD trainer method
def train_val_fn(self, loader_train, model: nn.Module, criterion: nn.Module, optimizer, scheduler) -> Tuple[Any, Union[float, Any]]:
scaler = torch.cuda.amp.GradScaler(enabled=self.cfg.amp_scaler)
model.train()
for step, batch in enumerate(tqdm(loader_train)):
optimizer.zero_grad(set_to_none=True)
inputs = batch['input_ids'].to(self.cfg.device, non_blocking=True)
labels = batch['labels'].to(self.cfg.device, non_blocking=True)
padding_mask = batch['padding_mask'].to(self.cfg.device, non_blocking=True)
mask_labels = None
if self.cfg.rtd_masking == 'SpanBoundaryObjective':
mask_labels = batch['mask_labels'].to(self.cfg.device, non_blocking=True)
with torch.cuda.amp.autocast(enabled=self.cfg.amp_scaler):
g_logit, d_inputs, d_labels = model.generator_fw(
inputs,
labels,
padding_mask,
mask_labels
)
d_logit = model.discriminator_fw(
d_inputs,
padding_mask
)
g_loss = criterion(g_logit.view(-1, self.cfg.vocab_size), labels.view(-1))
d_loss = criterion(d_logit.view(-1, 2), d_labels)
loss = g_loss + d_loss*self.cfg.discriminator_lambda
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
scheduler.step()
데이터로더로부터 받은 입력들을 생성자에 넣고 MLM 예측 결과, RTD 수행을 위해 필요한 새로운 라벨값을 반환 받는다. 그리고 이것을 다시 판별자의 입력으로 사용하고, 판별자의 예측 결과를 반환받아 서로 다른 두 모델에 대한 가중 손실합산을 구한 뒤, 옵티마이저에 보내고 최적화를 수행한다. 이 때, 처음에 데이터로더가 반환하는 입력 시퀀스와 라벨은 MLM의 그것과 동일하다,
구현하면서 가장 어려웠던게, 옵티마이저 및 스케줄러의 구성이었다. 두 개의 모델을 같은 스탭에서 학습시키는 경험이 처음이라서 처음에 모델 개수만큼 옵티마이저와 스케줄러 객체를 만들어줘야 한다고 생각했다. 특히 두 모델의 스케일이 다르기 때문에 서로 다른 옵티마이저, 스케줄러 도입으로 각기 다른 학습률을 적용하는게 정확할 것이라 생각했다.
하지만, 옵티마이저를 두 개 사용하는 것은 매우 많은 메모리를 차지할 뿐더러 논문에서 공개한 하이퍼파라미터 테이블을 보면 두 모델에 같은 학습률을 적용하고 있는 것을 알 수 있었다. 따라서 그에 맞게 같은 옵티마이저, 스케줄러를 사용해 동시에 두 모델이 학습되도록 파이프라인을 만들게 되었다.
추가로, 공개된 오피셜 코드 역시 단일 옵티마이저 및 스케줄러를 사용하는 것을 확인했다.
🌆 ELECTRA Module
import torch
import torch.nn as nn
from experiment.models.abstract_model import AbstractModel
from torch import Tensor
from typing import Tuple, Callable
from einops.layers.torch import Rearrange
from experiment.tuner.mlm import MLMHead
from experiment.tuner.sbo import SBOHead
from experiment.tuner.rtd import get_discriminator_input, RTDHead
from configuration import CFG
class ELECTRA(nn.Module, AbstractModel):
def __init__(self, cfg: CFG, model_func: Callable) -> None:
super(ELECTRA, self).__init__()
self.cfg = cfg
self.generator = model_func(cfg.generator_num_layers) # init generator
self.mlm_head = MLMHead(self.cfg)
if self.cfg.rtd_masking == 'SpanBoundaryObjective':
self.mlm_head = SBOHead(
cfg=self.cfg,
is_concatenate=self.cfg.is_concatenate,
max_span_length=self.cfg.max_span_length
)
self.discriminator = model_func(cfg.discriminator_num_layers) # init generator
self.rtd_head = RTDHead(self.cfg)
self.share_embed_method = self.cfg.share_embed_method # instance, es, gdes
self.share_embedding()
def share_embedding(self) -> None:
def discriminator_hook(module: nn.Module, *inputs):
if self.share_embed_method == 'instance': # Instance Sharing
self.discriminator.embeddings = self.generator.embeddings
elif self.share_embed_method == 'ES': # ES (Embedding Sharing)
self.discriminator.embeddings.word_embedding.weight = self.generator.embeddings.word_embedding.weight
self.discriminator.embeddings.abs_pos_emb.weight = self.generator.embeddings.abs_pos_emb.weight
self.discriminator.register_forward_pre_hook(discriminator_hook)
def generator_fw(
self,
inputs: Tensor,
labels: Tensor,
padding_mask: Tensor,
mask_labels: Tensor = None,
attention_mask: Tensor = None
) -> Tuple[Tensor, Tensor, Tensor]:
g_last_hidden_states, _ = self.generator(
inputs,
padding_mask,
attention_mask
)
if self.cfg.rtd_masking == 'MaskedLanguageModel':
g_logit = self.mlm_head(
g_last_hidden_states
)
elif self.cfg.rtd_masking == 'SpanBoundaryObjective':
g_logit = self.mlm_head(
g_last_hidden_states,
mask_labels
)
pred = g_logit.clone().detach()
d_inputs, d_labels = get_discriminator_input(
inputs,
labels,
pred,
)
return g_logit, d_inputs, d_labels
def discriminator_fw(
self,
inputs: Tensor,
padding_mask: Tensor,
attention_mask: Tensor = None
) -> Tensor:
d_last_hidden_states, _ = self.discriminator(
inputs,
padding_mask,
attention_mask
)
d_logit = self.rtd_head(
d_last_hidden_states
)
return d_logit
ELECTRA 모델 객체는 크게 임배딩 레이어 공유, 생성자 포워드, 판별자 포워드 파트로 나뉜다. 먼저 임베딩 레이어 공유는 크게 두 가지 방식으로 구현 가능하다. 하나는 임베딩 레이어 인스턴스 자체를 공유하는 방식으로, 생성자와 판별자의 스케일이 동일할 때 사용할 수 있다. 나머지는 단어 임베딩, 포지션 임베딩의 가중치 행렬만 공유하는 방식으로, 서로 스케일이 달라도 사용할 수 있다. 논문에서 제시하는 가장 효율적인 방법은 후자이며, 판별자의 임베딩 행렬이 생성자의 임베딩 행렬의 주소를 가리키도록 함으로서 구현 가능하다.
🌆 RTD Input Making
import torch
import torch.nn as nn
from torch import Tensor
from typing import Tuple
from configuration import CFG
def get_discriminator_input(inputs: Tensor, labels: Tensor, pred: Tensor) -> Tuple[Tensor, Tensor]:
""" Post Processing for Replaced Token Detection Task
1) get index of the highest probability of [MASK] token in pred tensor
2) convert [MASK] token to prediction token
3) make label for Discriminator
Args:
inputs: pure inputs from tokenizing by tokenizer
labels: labels for masked language modeling
pred: prediction tensor from Generator
returns:
d_inputs: torch.Tensor, shape of [Batch, Sequence], for Discriminator inputs
d_labels: torch.Tensor, shape of [Sequence], for Discriminator labels
"""
# 1) flatten pred to 2D Tensor
d_inputs, d_labels = inputs.clone().detach().view(-1), None # detach to prevent back-propagation
flat_pred, flat_label = pred.view(-1, pred.size(-1)), labels.view(-1) # (batch * sequence, vocab_size)
# 2) get index of the highest probability of [MASK] token
pred_token_idx, mlm_mask_idx = flat_pred.argmax(dim=-1), torch.where(flat_label != -100)
pred_tokens = torch.index_select(pred_token_idx, 0, mlm_mask_idx[0])
# 3) convert [MASK] token to prediction token
d_inputs[mlm_mask_idx[0]] = pred_tokens
# 4) make label for Discriminator
original_tokens = inputs.clone().detach().view(-1)
original_tokens[mlm_mask_idx[0]] = flat_label[mlm_mask_idx[0]]
d_labels = torch.eq(original_tokens, d_inputs).long()
d_inputs = d_inputs.view(pred.size(0), -1) # covert to [batch, sequence]
return d_inputs, d_labels
이제 마지막으로 판별자의 입력을 만드는 알고리즘에 대한 코드를 보자. 알고리즘은 다음과 같다.
- 1) 개별 마스킹 토큰에 대한 예측 토큰 구하기
- 로짓을 실제 토큰 인덱스로 변환
- 2) 모든 마스킹 부분에 예측 토큰들로 대체
- 3) 기존 입력과 2번으로 만들어진 시퀀스 비교해 라벨 생성
- 서로 같으면 0
- 서로 다르면 1 이렇게 만들어진 새로운 입력 시퀀스와 라벨을 ELECTRA 모델 인스턴스의 판별자 포워드 메서드에 인자로 전달하면 된다.
🌟 Future Work (읽고 구현하면서 느낀점 & 개선방향)
이렇게 ELECTRA 모델에 대한 구현까지 살펴봤다. 논문을 읽고 구현하면서 가장 의문스러웠던 부분은 임베딩 공유 방법이었다. 수학적으로 엄밀하게 계산하고 따져보지 못했지만, 직관적으로도 생성자의 MLM과 판별자의 RTD는 서로 성격이 상당히 다른 사전 학습 방법론이라는 것을 알 수 있다. 그렇다면 단순히 단어, 포지션 임베딩을 공유하는 경우 학습 방향성이 달라서 간섭이 발생하고 모델이 수렴하지 못할 여지가 생긴다. 이러한 줄다리기 현상(tag-of-war)을 어떻게 해결할 수 있을까에 대한 고민이 더 필요하다고 생각한다.
그래서 다음 포스팅에서는 이러한 줄다리기 현상을 해결하고자한 논문인 <DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing>을 리뷰해보고자 한다.
Leave a comment