
🪢 [DeBERTa-V3] DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing
![]() Updated:
Updated:
🔭 Overview
2021년 Microsoft에서 공개한 DeBERTa-V3은 기존 DeBERTa의 모델 구조는 그대로 유지하되, ELECTRA의 Generator-Discriminator 구조를 차용하여 전작 대비 성능을 향상 시킨 모델이다. ELECTRA에서 BackBone 모델로 BERT 대신 DeBERTa을 사용했다고 생각하면 된다. 거기에 더해 ELECTRA의 Tug-of-War 현상을 방지하기 위해 새로운 임베딩 공유 기법인 GDES(Gradient Disentagnled Embedding Sharing)방법을 제시했다.
이번 포스팅에서는 구현 코드와 함께 GDES에 대해서만 살펴보려 한다. ELECTRA, DeBERTa에 대해 궁금하다면 이전 포스팅을, 전체 구조에 대한 코드는 여기 링크를 통해 확인 가능하다.
🪢GDES: Gradient Disentangled Embedding Sharing
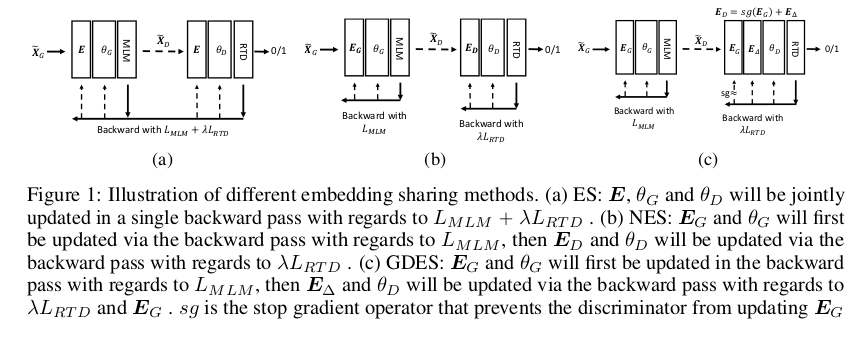
그림의 (a)가 기존 ELECTRA의 가중치 공유 방식, (c)가 GDES에 해당된다. 그림 속 모식도와 설명이 좀 복잡해 보이지만 아이디어는 매우 간단하다.
생성자와 판별자가 서로 포워드 패스 시점에는 단어, 위치 임베딩을 공유하되, 백워드 패스 시점에서는 공유되지 못하도록 하여, 판별자의 학습 결과에 의해 생성자의 단어 임베딩, 위치 임베딩이 업데이트 되지 못하도록 하지는 것이다. 오직 생성자의 MLM 학습에 의해서만 단어 및 위치 임베딩이 업데이트 되어야 한다.
\[E_{D} = \text{sg}(E_{G}) + E_{\Delta}\]필자가 추정하기로는 Skip-Connection에서 영감을 받지 않았나 싶은 이 수식은, 생성자의 임베딩에 잔차값들을 더해 판별자의 임베딩 행렬이 RTD에 최적화 되도록 설계 되었다. 여기서 sg() 는 stop gradient를 의미한다. 다시 말해, 생성자의 임베딩 가중치를 판별자 학습에 사용하되, 해당 시점에서는 계산 그래프 작성을 중단시켜 판별자의 학습 결과(이진 분류 손실)가 생성자의 임베딩 가중치에 영향을 미치지 못하도록 한 것이다.
이러한 아이디어는 실제로 어떻게 코드로 구현해야할까, 아래 코드와 함께 살펴보자.
👩💻 Implementation by Pytorch
ELECTRA 모듈 __init__의 share_embed_method에 따라 브랜치가 발생하는 구간과, 아래 share_embedding() 메서드에 주목해보자.
import torch
import torch.nn as nn
from experiment.models.abstract_model import AbstractModel
from torch import Tensor
from typing import Tuple, Callable
from einops.layers.torch import Rearrange
from experiment.tuner.mlm import MLMHead
from experiment.tuner.sbo import SBOHead
from experiment.tuner.rtd import get_discriminator_input, RTDHead
from configuration import CFG
class ELECTRA(nn.Module, AbstractModel):
""" If you want to use pure ELECTRA, you should set share_embedding = ES
elif you want to use ELECTRA with GDES, you should set share_embedding = GDES
GDES is new approach of embedding sharing method from DeBERTa-V3 paper
Args:
cfg: configuration.CFG
model_func: make model instance in runtime from config.json
Var:
cfg: configuration.CFG
generator: Generator, which is used for generating replaced tokens for RTD
should select backbone model ex) BERT, RoBERTa, DeBERTa, ...
discriminator: Discriminator, which is used for detecting replaced tokens for RTD
should select backbone model ex) BERT, RoBERTa, DeBERTa, ...
share_embedding: whether or not to share embedding layer (word & pos) between Generator & Discriminator
self.word_bias: Delta_E in paper
self.abs_pos_bias: Delta_E in paper
self.rel_pos_bias: Delta_E in paper
References:
https://arxiv.org/pdf/2003.10555.pdf
https://arxiv.org/pdf/2111.09543.pdf
https://github.com/google-research/electra
"""
def __init__(self, cfg: CFG, model_func: Callable) -> None:
super(ELECTRA, self).__init__()
self.cfg = cfg
self.generator = model_func(cfg.generator_num_layers) # init generator
self.mlm_head = MLMHead(self.cfg)
if self.cfg.rtd_masking == 'SpanBoundaryObjective':
self.mlm_head = SBOHead(
cfg=self.cfg,
is_concatenate=self.cfg.is_concatenate,
max_span_length=self.cfg.max_span_length
)
self.discriminator = model_func(cfg.discriminator_num_layers) # init generator
self.rtd_head = RTDHead(self.cfg)
self.share_embed_method = self.cfg.share_embed_method # instance, es, gdes
if self.share_embed_method == 'GDES':
self.word_bias = nn.Parameter(
torch.zeros_like(self.discriminator.embeddings.word_embedding.weight, device=self.cfg.device)
)
self.abs_pos_bias = nn.Parameter(
torch.zeros_like(self.discriminator.embeddings.abs_pos_emb.weight, device=self.cfg.device)
)
delattr(self.discriminator.embeddings.word_embedding, 'weight')
self.discriminator.embeddings.word_embedding.register_parameter('_weight', self.word_bias)
delattr(self.discriminator.embeddings.abs_pos_emb, 'weight')
self.discriminator.embeddings.abs_pos_emb.register_parameter('_weight', self.abs_pos_bias)
if self.cfg.model_name == 'DeBERTa':
self.rel_pos_bias = nn.Parameter(
torch.zeros_like(self.discriminator.embeddings.rel_pos_emb.weight, device=self.cfg.device)
)
delattr(self.discriminator.embeddings.rel_pos_emb, 'weight')
self.discriminator.embeddings.rel_pos_emb.register_parameter('_weight', self.rel_pos_emb)
self.share_embedding()
def share_embedding(self) -> None:
def discriminator_hook(module: nn.Module, *inputs):
if self.share_embed_method == 'instance': # Instance Sharing
self.discriminator.embeddings = self.generator.embeddings
elif self.share_embed_method == 'ES': # ES (Embedding Sharing)
self.discriminator.embeddings.word_embedding.weight = self.generator.embeddings.word_embedding.weight
self.discriminator.embeddings.abs_pos_emb.weight = self.generator.embeddings.abs_pos_emb.weight
if self.cfg.model_name == 'DeBERTa':
self.discriminator.embeddings.rel_pos_emb.weight = self.generator.embeddings.rel_pos_emb.weight
elif self.share_embed_method == 'GDES': # GDES (Generator Discriminator Embedding Sharing)
g_w_emb = self.generator.embeddings.word_embedding
d_w_emb = self.discriminator.embeddings.word_embedding
self._set_param(d_w_emb, 'weight', g_w_emb.weight.detach() + d_w_emb._weight)
g_p_emb = self.generator.embeddings.abs_pos_emb
d_p_emb = self.discriminator.embeddings.abs_pos_emb
self._set_param(d_p_emb, 'weight', g_p_emb.weight.detach() + d_p_emb._weight)
if self.cfg.model_name == 'DeBERTa':
g_rp_emb = self.generator.embeddings.rel_pos_emb
d_rp_emb = self.discriminator.embeddings.rel_pos_emb
self._set_param(d_rp_emb, 'weight', g_rp_emb.weight.detach() + d_rp_emb._weight)
self.discriminator.register_forward_pre_hook(discriminator_hook)
@staticmethod
def _set_param(module, param_name, value):
module.register_buffer(param_name, value)
def generator_fw(self, inputs: Tensor, labels: Tensor, padding_mask: Tensor, mask_labels: Tensor = None, attention_mask: Tensor = None) -> Tuple[Tensor, Tensor, Tensor]:
g_last_hidden_states, _ = self.generator(
inputs,
padding_mask,
attention_mask
)
if self.cfg.rtd_masking == 'MaskedLanguageModel':
g_logit = self.mlm_head(
g_last_hidden_states
)
elif self.cfg.rtd_masking == 'SpanBoundaryObjective':
g_logit = self.mlm_head(
g_last_hidden_states,
mask_labels
)
pred = g_logit.clone().detach()
d_inputs, d_labels = get_discriminator_input(
inputs,
labels,
pred,
)
return g_logit, d_inputs, d_labels
def discriminator_fw(self, inputs: Tensor, padding_mask: Tensor,attention_mask: Tensor = None) -> Tensor:
d_last_hidden_states, _ = self.discriminator(
inputs,
padding_mask,
attention_mask
)
d_logit = self.rtd_head(
d_last_hidden_states
)
return d_logit
먼저 __init__의 브랜치 구간을 살펴보자. word_bias, pos_bias를 만들어 register_parameter화를 하고 있다. 새롭게 생성되어 _weight이란 이름으로 생성자의 파라미터가 된 두 가중치가 바로 $E_{\Delta}$ 가 된다.
다음 share_embedding() 메서드를 보자. $E_{G}$ 에 torch.detach()를 사용해 수식의 stop gradient 효과를 적용한다. 그리고 두 가중치를 더하고, torch.register_buffer를 호출해 포워드 패스에 활용은 되지만 백워드 패스에 그라디언트가 해당 가중치를 업데이트 하지 못하도록 설정한다. 그리고 마지막에 torch.register_forward_pre_hook을 호출하는데, 그 이유는 $E_{G}$ 에 torch.detach() 를 사용했기 때문에 현재 판별자의 버퍼에 있는 $E_{G}$ 는 이전 시점의 생성자 MLM 손실에 의해 새롭게 업데이트 $E_{G}$ 가 아니다. 따라서 매번 판별자의 포워드 패스가 호출(시작)되는 시점에 업데이트 된 $E_{G}$ 를 반영해 RTD를 수행할 수 있도록 하기 위해 register_forward_pre_hook 를 사용했다.
🤔 GDES Experiment
GDES가 제대로 구현되었는지, 논문 주장대로 판별자 학습 결과가 간섭을 발생시키지 않는지 확인하기 위해 한가지 실험을 진행했다. 실험 내용은 이렇다. 만약 GDES가 의도대로 구현된게 맞다면, 인코더 모델의 MLM 학습 결과 추이와 ELECTRA의 생성자 학습 결과 추이 양상이 유사해야 한다. 만약 최적화 추세가 다르다면, 필자가 잘못 구현했거나, 저자의 주장과 다르게 간섭이 발생하는 것이라 볼 수 있을 것이다. Backbone을 DeBERTa로 두고 각각 학습을 진행했다. 모든 하이퍼 파라미터를 고정한 뒤, 학습 초반 120스탭에 대한 결과 추이를 비교해봤다.
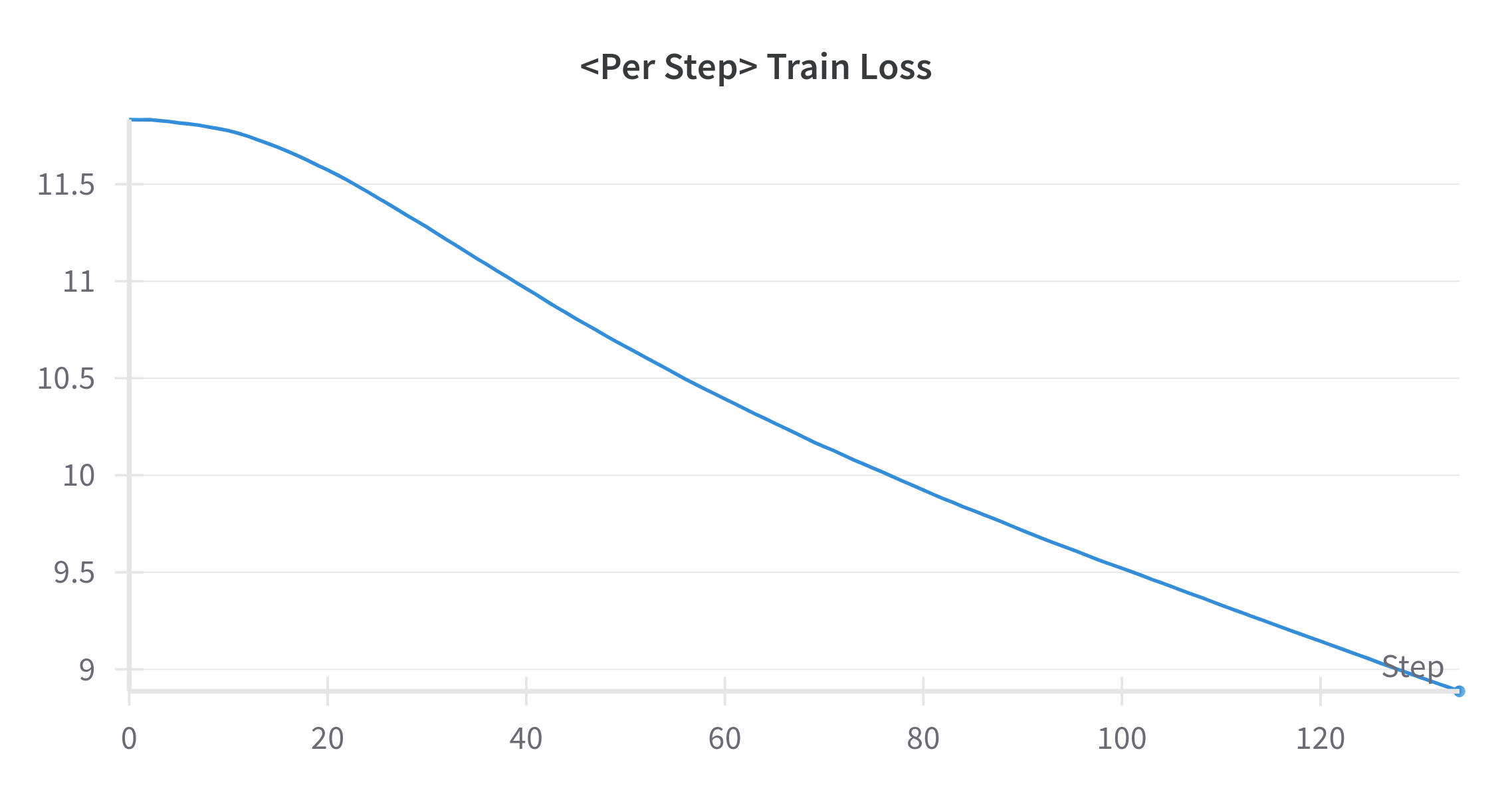
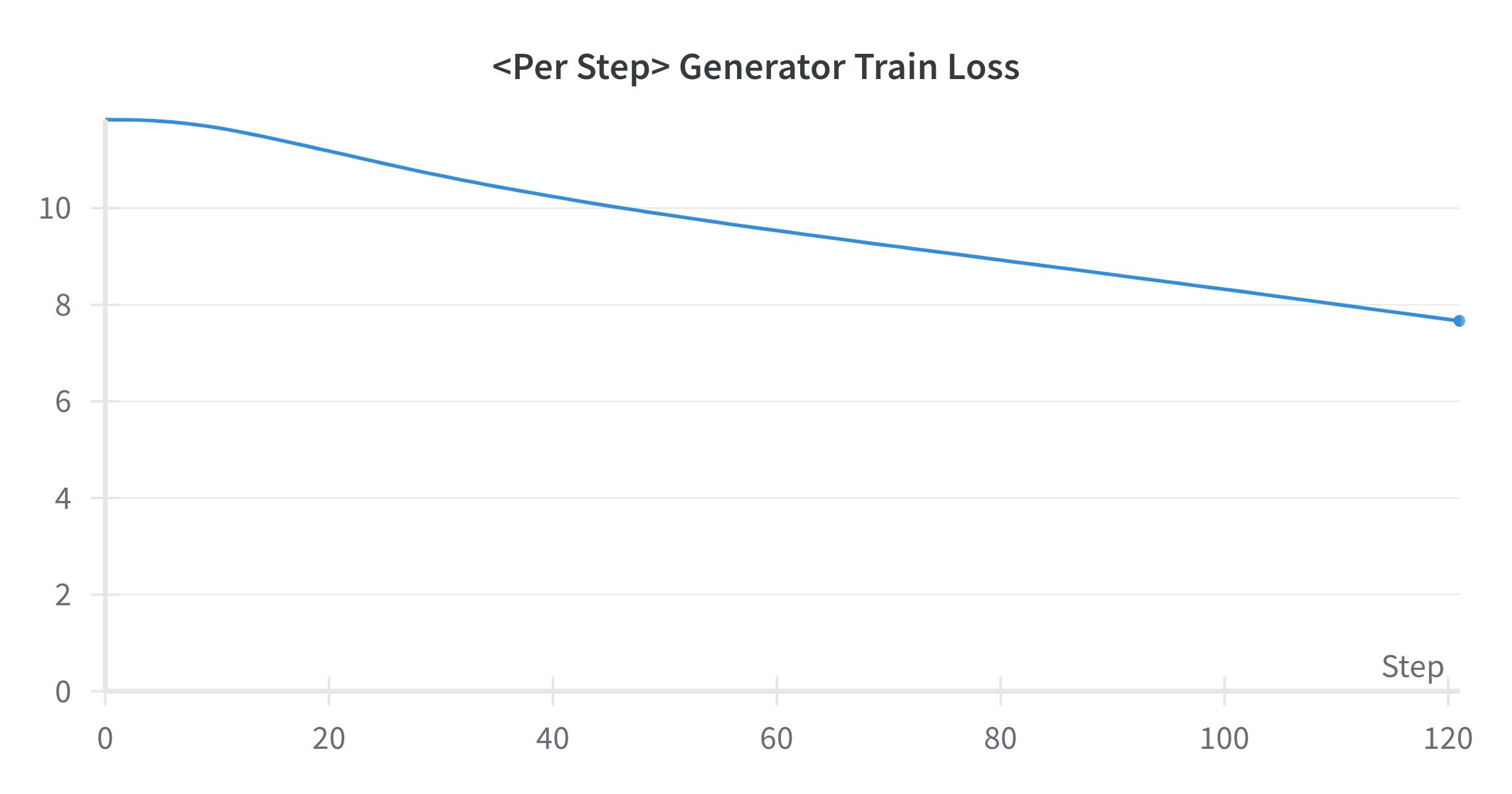
미처 까먹고 torch.backends.cudnn.deterministic = False로 두고 실험을 진행하여, 생성자의 수렴이 좀 더 빨리 진행되는 양상을 보이고 있다. 아마도 생성자 학습을 할 때 cudnn 이 열심히 일을 한 것 같댜. 수렴 속도에는 차이가 조금 나지만, 최적화 되는 추세 자체는 동일한 것을 알 수 있다.
따라서 GDES를 사용하면 간섭이 발생하지 않아 Tug-of-War 현상을 방지할 수 있다. 다만, 실험이 다소 엄밀하지 못한 측면이 있다. 추후에 좀 더 엄밀한 증명을 할 수 있는 실험 방법을 생각해봐야겠다.
Leave a comment